编译器,LLVM与IR
当代的编译器设计遵循下面这张图的架构:

(图片来源:http://www.aosabook.org/en/llvm.html)
如上图所示,编译器被拆解成上面三部分:前端,优化器,后端。
前端就是lexer加上parser,设计目标是把源代码转成数据结构,一般是AST的结构,即Abstract Syntax Tree,用来表示源代码当中的各种代码的层级关系。比如这段代码:
int main() {
int x;
x = 3;
}
转换成AST以后,如下图所示:
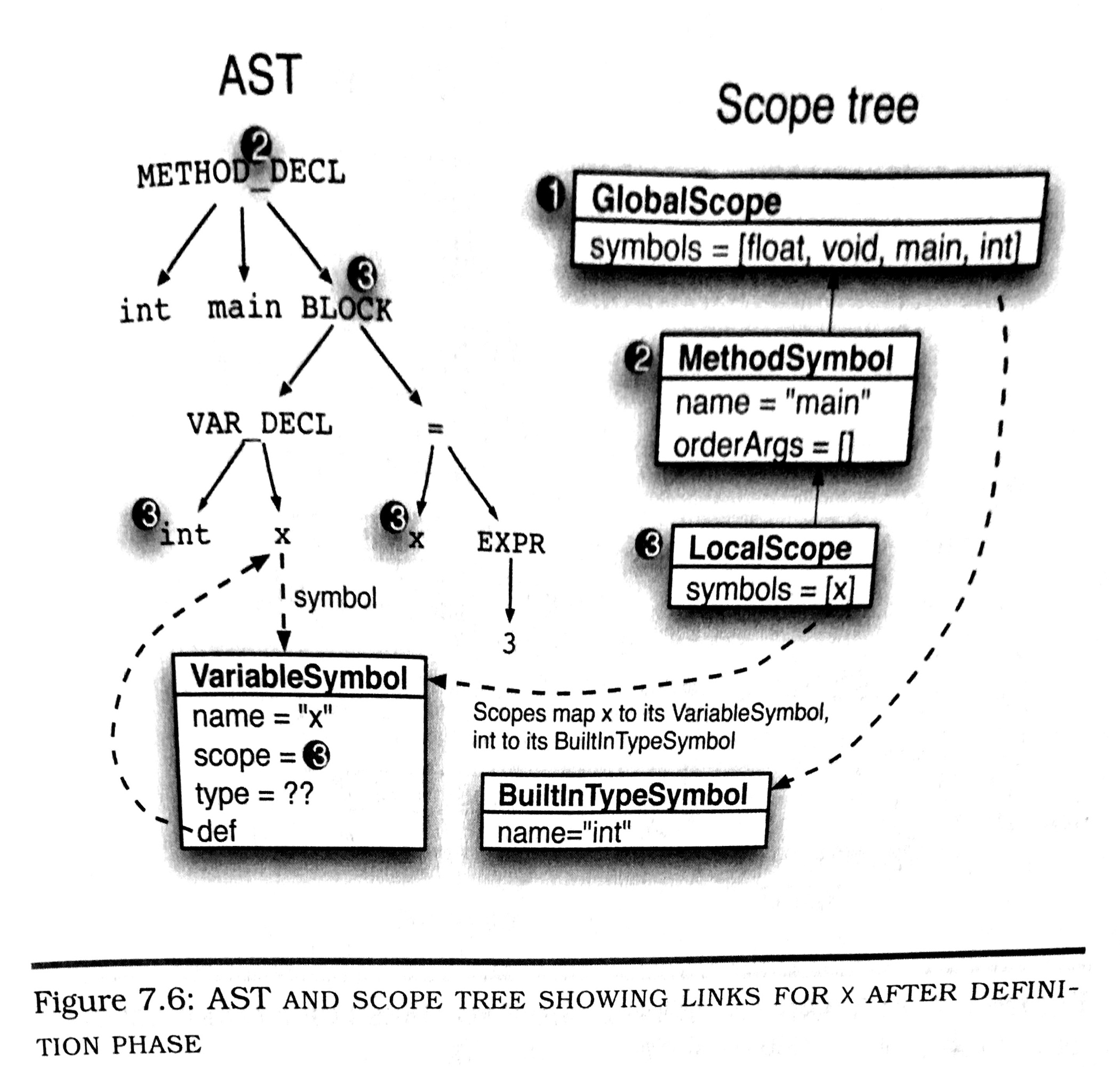
(图片来源:Parr, T. (2009). Language implementation patterns: create your own domain-specific and general programming languages. Pragmatic Bookshelf.)
从上图中可以看到源代码内在的树形结构。而图中右半部分则是保存相关和变量所需要的一些数据结构(图中以Java classes的形式来实现)。
因此,左边的树形结构是AST,而右边这些数据结构就是Symbol Tables,就是保存代码里面各种结构,参数,符号等数据的一张表格。
可以看到,前端最终要做的就是把源代码转化成这些数据结构。接下来看Optimizer,这块的作用是把前端的转化而成的数据结构进行优化,但前提是不改变源代码原本要表达的逻辑。
优化这块可以做的,比如去除掉永远运行不到的代码,把一些写得冗长不合理的逻辑改短,同时不改变逻辑本身,等等。
最后是后端。后端就是把中间的数据结构转化成目标平台的源代码。这部分要用到的技术也是独立的一块。
这样设计编译器的好处是什么?实际上就是前端和后端可以各自独立实现,独立维护。因为前端和后端所用到的技术各自都比较独立,所以对于维护编译器这样复杂的项目来说,模块化是必要的。
还有一个更重要的原因,就是这样的设计可以让一个编译器支持多语言,多平台的设计。类似下图所示:
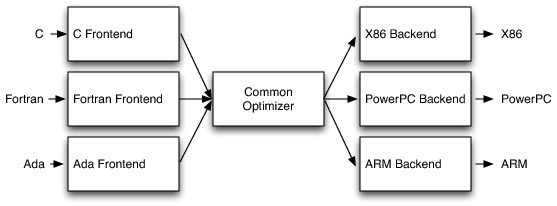
如上所示,通过这样的架构,我们可以让一个编译器支持多种源代码,并且在多个平台上面编译成不同CPU架构的目标代码。
但GCC再实际设计的时候,前端和后端没能分得太开,也就是中间的数据结构层面没设计好,导致很多数据在前端以及后端耦合在了一起。所以在GCC实际的实现中,为了支持一个新的语言,或者为了支持一个新的目标平台,就变得特别困难。
而LLVM为了解决这个问题,也就是把前端和后端给拆分开,就在中间层明确定义一种抽象的语言,这个语言就叫做IR。定义了IR以后,前端的任务就是负责最终生成IR,优化器就负责优化生成的IR,而后端的任务就是把IR给转化成目标平台的语言。
因此,前端,优化器,后端,之间,唯一交换的数据就是IR,这样就实现了彻底的拆分。
接下来玩玩LLVM的中间语言IR。
其实IR和汇编差不多,但是少了很多硬件本身带来的制约,也去掉很多平台相关的东西1。
比如IR里面的寄存器是无限的,可以随意使用,在后端转化成具体硬件平台的目标代码的时候,才会通过算法把无限多的寄存器转化成有限数目的寄存器的相关代码。
此外,IR的内存模型相比具体的硬件平台,限制也更松;最后,IR的指令也会少很多针对具体硬件限制所产成的一些特定的指令,更是更偏向于逻辑本身。
接下来我们来具体看看IR的代码。最省事的方法就是写一段C代码,然后用clang给编译成IR代码。clang是llvm的一个前端实现,如果你是在Fedora Linux下安装它,相关的LLVM组件也都会作为依赖被安装好。下面是clang这个package的截图:
安装好了clang和相关的组件以后,可以写一段C语言的代码,如下图所示:
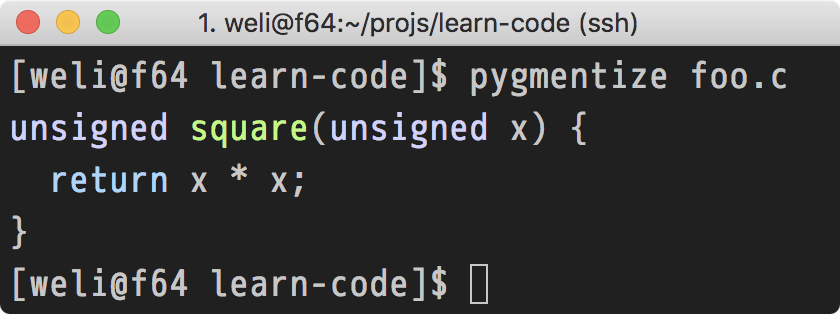
如上图所示,这个c代码是一个函数的定义,里面有参数,简单的运算,和返回值的类型定义等等。我们要使用clang命令把这段代码编译成IR代码,而不是最终的可执行文件。下面是编译命令:
$ clang -Os -S -emit-llvm foo.c -o foo.ll
用上面的命令,我们得到了包含IR代码的文件foo.ll。下面是这个文件的内容:
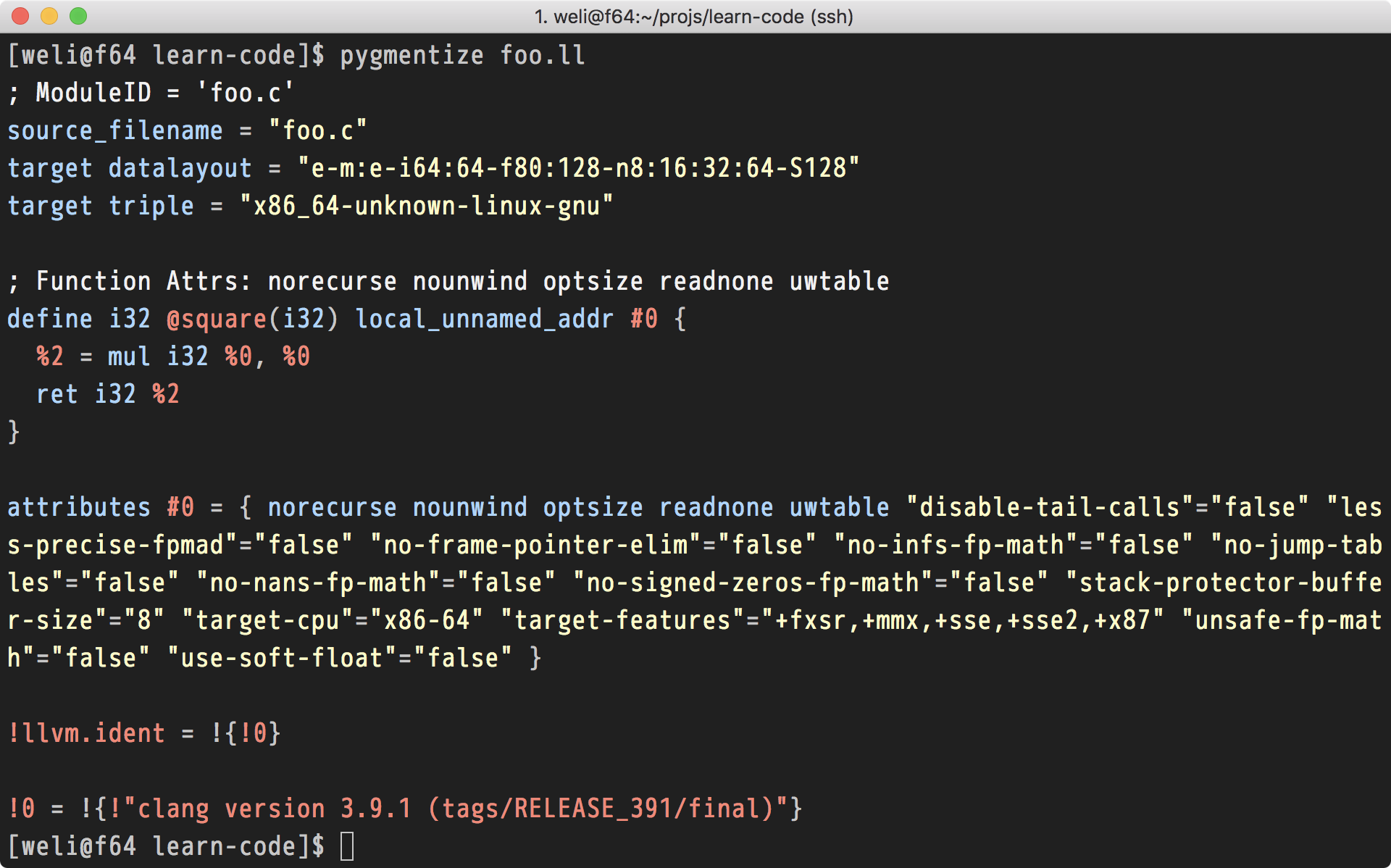
这里面包含了很多meta-information,重点的部分是对应原C代码的内容:
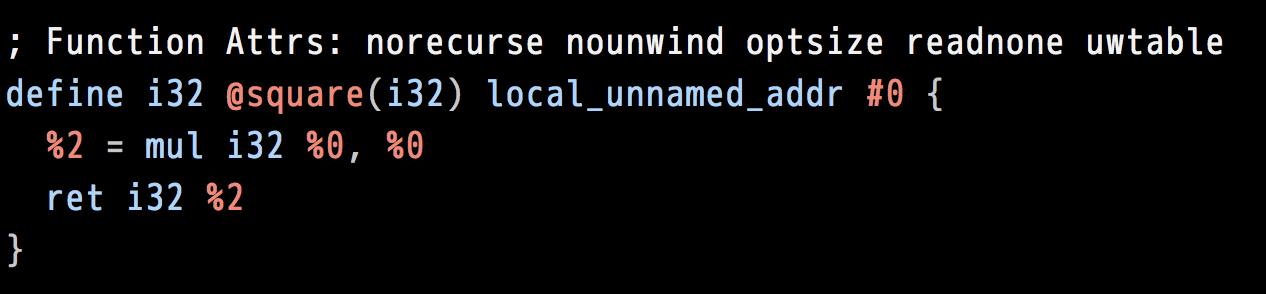
从上面的代码当中,我们可以看到,IR代码内置了一些数据格式,比如这里面用到的i32,对应我们C代码当中的unsigned;还可以看到一些IR的指令,比如相乘指令就是mul;以及寄存器的调用,比如%0,%2,等等。其实和汇编语言是高度相似的。
IR的语言规范特别庞大,网上的权威参考资料在这里:
https://llvm.org/docs/LangRef.html
相当于字典了,需要用的时候可以查阅。
IR语言的设计目的就是平台无关,理论上支持各种源代码。因为只有这样,LLVM才能够实现多种语言的编译。但在实际的应用领域,LLVM这个架构体系的主力使用者还是C,C++。而C以及C++在后端需要能够在各种硬件平台上面编译,所以LLVM作为GCC的替代品,更易于维护一些,这主要得益于IR的设计。
当然,把前端和后端彻底拆分开,可能最终生成的目标代码相比gcc编译出来的代码效率低一些(甚至于是否如此根本无法准确评估,因为复杂的代码编译里面涉及的层面太多,很难有个确定的评估结果),但是从编译器本身的可维护性,可扩展性这点上来看,llvm已经优于gcc并胜出。
此外,我们还要看到,虽然有了IR,但并不是所有的语言都有意愿去把自己的编译系统移植到llvm框架上面来。比如Java,有自己成熟的,自成体系的一套复杂的编译系统,而后面支撑的还有自己的VM(虚拟机)生态环境。
还有比如Clojure,用的是JVM这套,也很难有意愿去把llvm这边给很完善地支撑实现起来。再比如Lisp或者Ruby,已经有自己的一套生态环境,也不太会去有大的社区力量去费力支持llvm。
所以说很多所谓的技术问题,其实是个生态问题。比如Java,大公司的很多钱投入到里面,做自己的生态环境,支撑llvm的价值不大。
而Ruby,本身是定义了自己的YARV虚拟机指令,这种基于虚拟机的语言平台,一般编译系统是跟着后面的虚拟机搭配着来,所以既不需要llvm这么重的架构,也没必要给自己找麻烦,去把本来就已经是抽象的虚拟机指令的yarv格式,前面再加一层IR指令。
此外,很多时候,有些语言特性,未必就使用IR格式作为中间格式。比如Lisp的语言实现本身就对parser非常友好,也没必要用到llvm这么重的架构(具体的编译原理知识后续文章和大家慢慢聊)。
-
https://idea.popcount.org/2013-07-24-ir-is-better-than-assembly/ ↩