MacOS下apache-spark的安装和配置过程
本文介绍apache-spark在macos环境下的使用。首先在homebrew下提供apache-spark的安装包:
$ brew info apache-spark
apache-spark: stable 2.3.1, HEAD
Engine for large-scale data processing
https://spark.apache.org/
/usr/local/Cellar/apache-spark/2.3.0 (1,083 files, 245MB)
Built from source on 2018-05-10 at 11:58:26
/usr/local/Cellar/apache-spark/2.3.1 (1,060 files, 244.5MB) *
Built from source on 2018-09-09 at 22:00:23
From: https://github.com/Homebrew/homebrew-core/blob/master/Formula/apache-spark.rb
==> Requirements
Required: java = 1.8 ✔
==> Options
--HEAD
Install HEAD version
==> Analytics
install: 6,302 (30d), 13,764 (90d), 56,513 (365d)
install_on_request: 5,793 (30d), 12,948 (90d), 51,674 (365d)
可以执行安装命令进行安装:
$ brew install apache-spark
安装好以后,可以查看安装的版本:
$ find /usr/local/ | grep apache-spark | head
/usr/local//Homebrew/Library/Taps/homebrew/homebrew-core/Formula/apache-spark.rb
/usr/local//var/homebrew/locks/apache-spark.formula.lock
/usr/local//var/homebrew/linked/apache-spark
/usr/local//opt/apache-spark
/usr/local//Cellar/apache-spark
/usr/local//Cellar/apache-spark/2.3.1
/usr/local//Cellar/apache-spark/2.3.1/INSTALL_RECEIPT.json
/usr/local//Cellar/apache-spark/2.3.1/LICENSE
/usr/local//Cellar/apache-spark/2.3.1/bin
/usr/local//Cellar/apache-spark/2.3.1/bin/spark-shell
我机器上安装的是版本2.3.1。安装完成之后还要进行一些设置工作,先是要在.bash_profile里面添加两行配置:
export SPARK_HOME=/usr/local/Cellar/apache-spark/2.3.1/libexec
export PATH=/usr/local/Cellar/apache-spark/2.3.1/libexec/sbin/:$PATH
这样就把spark的环境路径等等设置好了。接下来还要设置一下spark的各种脚本的执行权限:
$ pwd
/usr/local/Cellar/apache-spark/2.3.1/libexec/sbin
$ chmod a+x *
这样,spark的脚本的执行权限就都设置好了:
接下来可以启动spark服务试试看:
$ start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/Cellar/apache-spark/2.3.1/libexec/logs/spark-weli-org.apache.spark.deploy.master.Master-1-pro.local.out
spark是根据hostname来绑定服务的,这一点我们可以通过查看start-master.sh学习到:
$ which start-master.sh
/usr/local/Cellar/apache-spark/2.3.1/libexec/sbin//start-master.sh
注意脚本中三个变量的设置,分别是SPARK_MASTER_PORT,SPARK_MASTER_HOST和SPARK_MASTER_WEBUI_PORT:
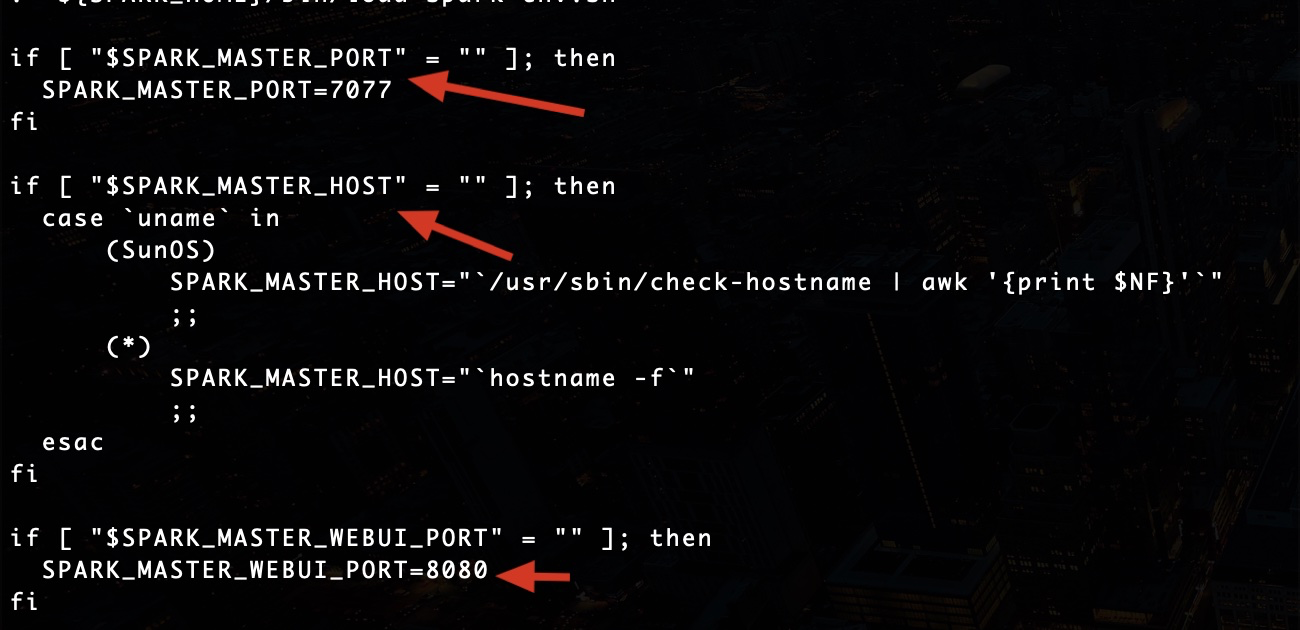
通过上面的脚本设置,可以知道SPARK_MASTER_HOST是通过hostname -f命令来设置的。因此我们也可以通过这个命令来确认绑定的主机名:
$ hostname -f
pro.local
上面可以看到我的主机名是pro.local。上面的脚本可以看到SPARK_MASTER_PORT是7077,所以可以知道master默认绑定的端口是7077。通过这些信息,我们可以访问到master的端口:
$ telnet pro.local 7077
Trying 192.168.20.241...
Connected to pro.local.
Escape character is '^]'.
可以看到spark的master节点已经绑定到相关的hostname和端口,并可以接收请求了。
接下来我们可以撰写python代码1如下:
# spark-basic.py
from pyspark import SparkConf
from pyspark import SparkContext
MASTER_NODE_HOSTNAME = 'pro.local'
conf = SparkConf()
conf.setMaster('spark://%s:7077' % MASTER_NODE_HOSTNAME)
conf.setAppName('spark-basic')
sc = SparkContext(conf=conf)
print(sc.textFile("/tmp/foo.json"))
上面这个代码向本地的spark master node提交任务,任务内容是读取/tmp/foo.json这个文件。我们可以创建这个文件以备使用:
$ echo "{'foo':'bar'}" > /tmp/foo.json
创建完成后,还要做些准备工作。上面这个代码用到了pyspark这个library,因此要求本地的python安装了这个library。Homebrew在安装apache-spark的时候也安装了python的相关library:
$ pwd
/usr/local
$ find . | grep pyspark | head
./bin/pyspark
./Cellar/apache-spark/2.3.1/bin/pyspark
./Cellar/apache-spark/2.3.1/libexec/bin/pyspark
./Cellar/apache-spark/2.3.1/libexec/python/pyspark.egg-info
./Cellar/apache-spark/2.3.1/libexec/python/pyspark.egg-info/PKG-INFO
./Cellar/apache-spark/2.3.1/libexec/python/pyspark.egg-info/SOURCES.txt
./Cellar/apache-spark/2.3.1/libexec/python/pyspark.egg-info/requires.txt
./Cellar/apache-spark/2.3.1/libexec/python/pyspark.egg-info/top_level.txt
./Cellar/apache-spark/2.3.1/libexec/python/pyspark.egg-info/dependency_links.txt
./Cellar/apache-spark/2.3.1/libexec/python/pyspark
因此我们只需要使用配套提供的这个pyspark的library就可以了。具体的方法是把上面这个python的库给引入到python的路径中来。我们可以分析pyspark脚本中,python库的路径设置。分析过程如下:
$ which pyspark
/usr/local/bin/pyspark
$ cat /usr/local/bin/pyspark
#!/bin/bash
JAVA_HOME="$(/usr/libexec/java_home --version 1.8)" exec "/usr/local/Cellar/apache-spark/2.3.1/libexec/bin/pyspark" "$@"
$ cat /usr/local/Cellar/apache-spark/2.3.1/libexec/bin/pyspark | grep PYTHONPATH
export PYTHONPATH="${SPARK_HOME}/python/:$PYTHONPATH"
export PYTHONPATH="${SPARK_HOME}/python/lib/py4j-0.10.7-src.zip:$PYTHONPATH"
看到了设置方法,我们就可以使用上面的设置,然后调用python命令,执行我们的spark-basic.py任务了:
$ export PYTHONPATH="${SPARK_HOME}/python/:$PYTHONPATH"
$ export PYTHONPATH="${SPARK_HOME}/python/lib/py4j-0.10.7-src.zip:$PYTHONPATH"
$ python spark-basic.py
2018-10-28 18:22:38 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
2018-10-28 18:22:38 WARN Utils:66 - Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
/tmp/foo.json MapPartitionsRDD[1] at textFile at NativeMethodAccessorImpl.java:0
可以看到我们的spark-basic.py任务被执行了。以上就是一个apache-spark在macos上的安装,配置和使用过程。