Adventures in JDBC and the PostgreSQL JDBC driver: Part 4 - Connection pooling in JDBC
Adventures in JDBC and the PostgreSQL JDBC driver: Part 4 - Connection pooling in JDBC
In the previous articles, we have learned the basic aspects of the JDBC specification and the implementation of the PostgreSQL driver. In this article, I’d like to go on checking another important part of the JDBC specification(JDBC™ 4.1 Specification): Connection pooling.
In JDBC specification, it defines a three-tier layer structure for the users to get connection from a managed data source pool. Here is the diagram from the specification:
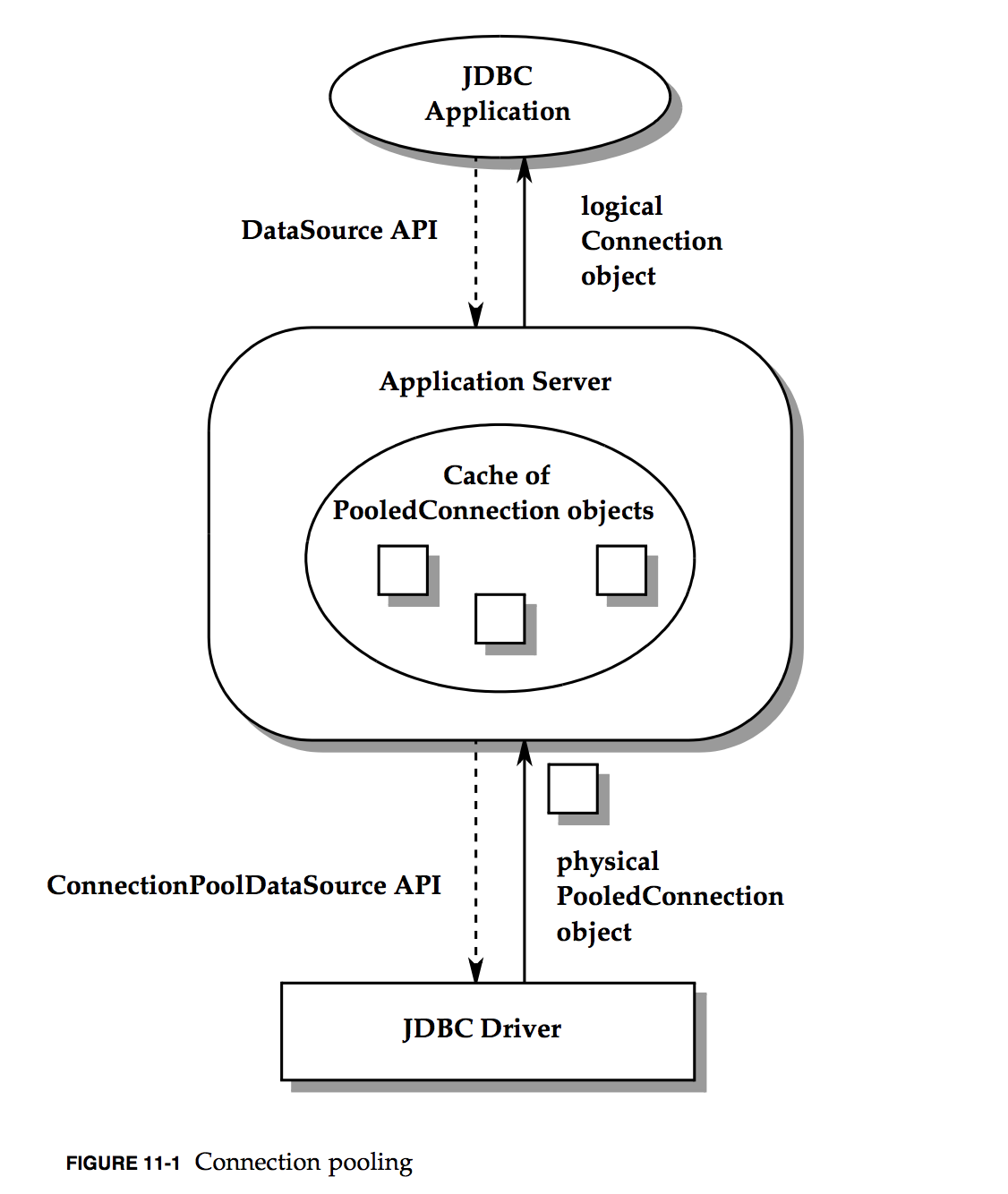
In above diagram, we can see the data source is designed to be provided by application server. For example, Wildfly as an application server should take the responsibility to provide a database connection pool to the users. On the JDBC driver layer, it needs to implement two interfaces defined by JDBC specification. Here is the class diagram of the two interfaces:
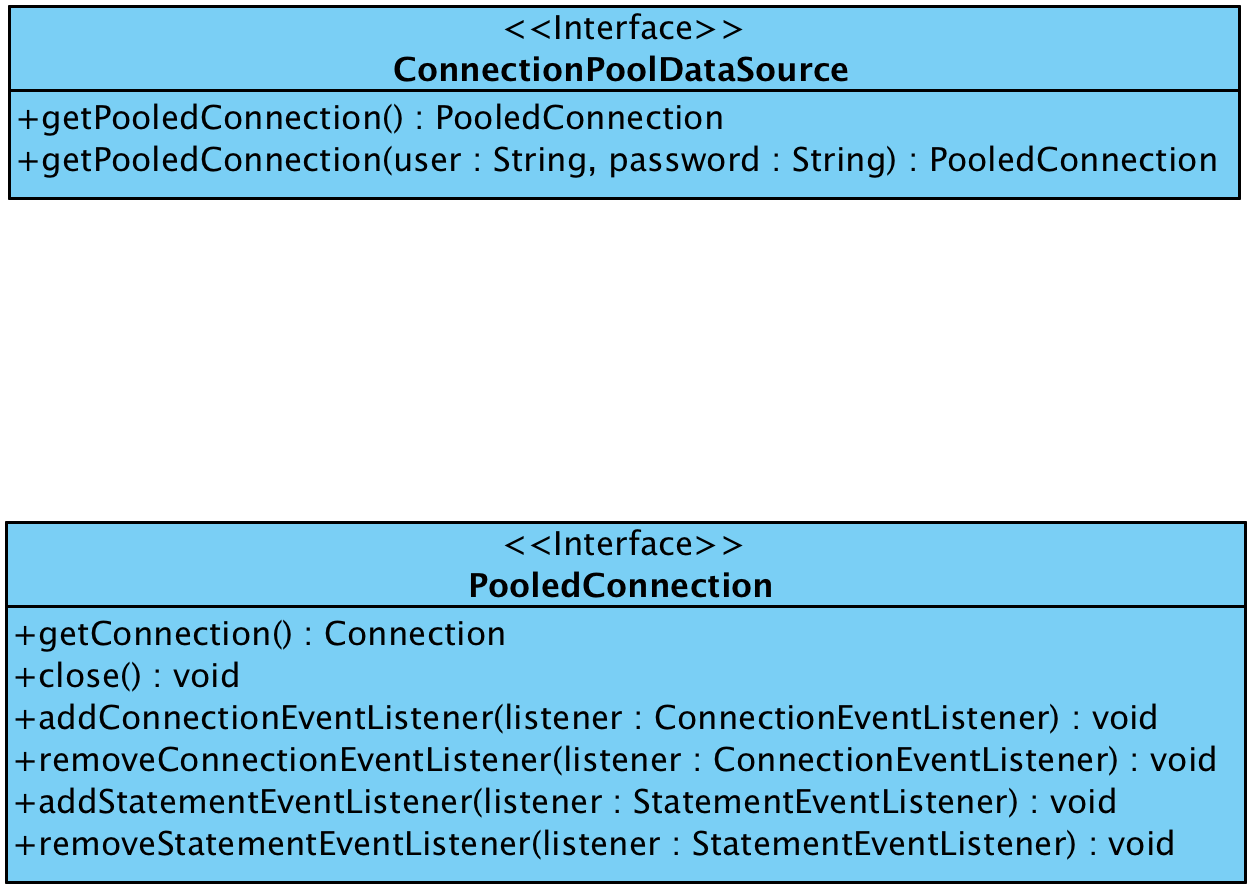
The above diagram shows the two interfaces from JDK source that should be implemented by the JDBC driver, which are javax.sql.PooledConnection and javax.sql.ConnectionPoolDataSource.
From the above diagram, we can see the ConnectionPoolDataSource interface defines a getPooledConnection() method that will return a javax.sql.PooledConnection typed data.
The PooledConnection interface defines the getConnection() method that will return a java.sql.Connection typed data.
The purpose of the design is to allow the implementation of the PooledConnection and ConnectionPoolDataSource to manage the underlying Connection to the database. In this way, the JDBC driver can handle the Connection instance returned from PooledConnection to manage its lifecycle the data pool.
Here is the class diagram about the implementation of the above two interfaces in PostgreSQL JDBC driver:
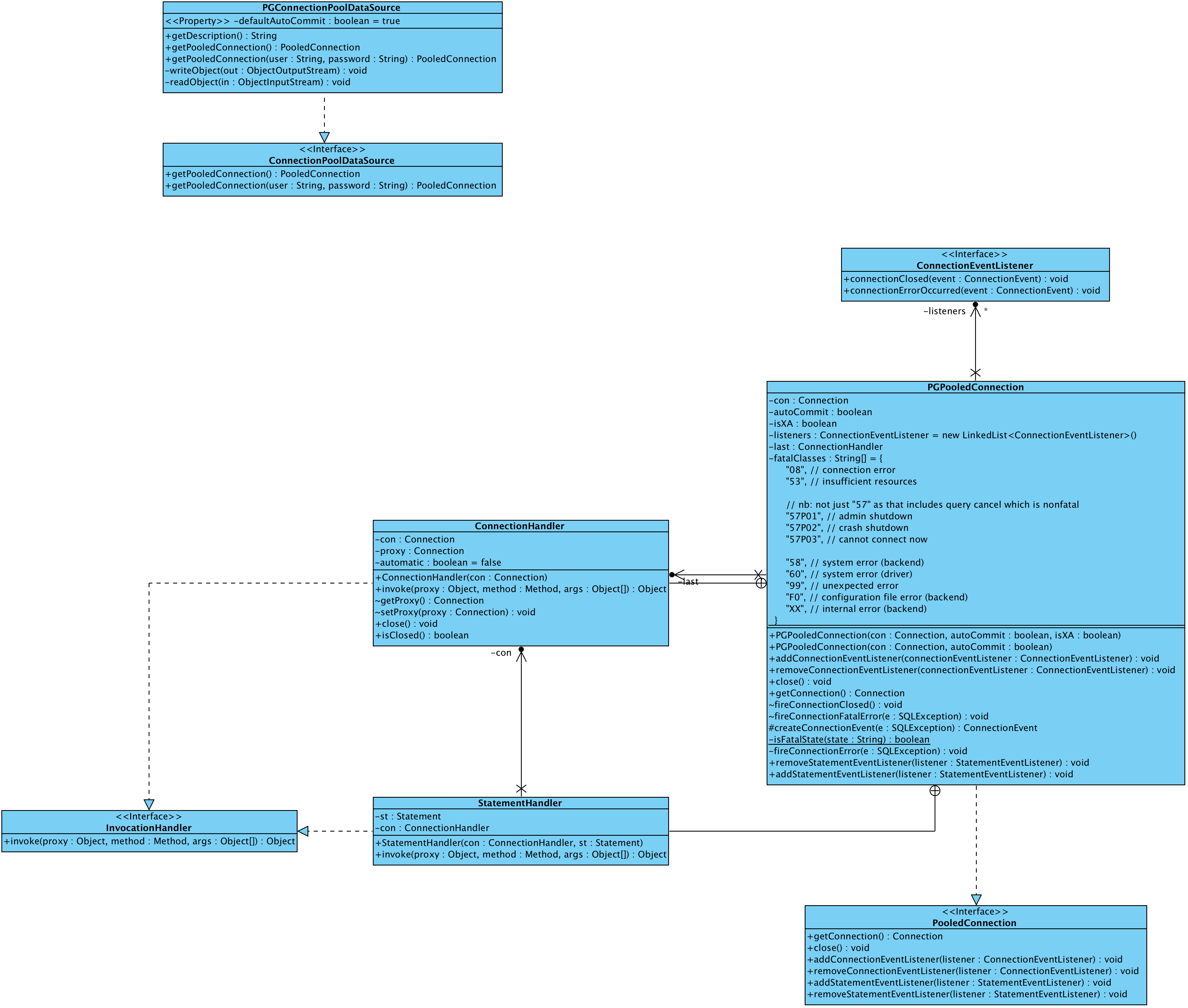
The above diagram shows the implementation of the interfaces in the driver. The org.postgresql.ds.PGPooledConnection implements the javax.sql.PooledConnection interface, and the org.postgresql.ds.PGConnectionPoolDataSource implements the javax.sql.ConnectionPoolDataSource. We will check the design of these two classes later in the article.
These two interfaces do not care about the detail pool implementation, and usually in application server the connection pool implementation can be configured and replaced with multiple choices.
In this article, I won’t use an application server as the datasource provider. In PostgreSQL JDBC driver, it provides a sample pooling implementation class named org.postgresql.ds.PGPoolingDataSource. We will use it as our demonstration implementation in this article.
Firstly, let’s write a class to use the org.postgresql.ds.PGPoolingDataSource to fetch a connection from the pool:
package io.weinan.jdbc;
import org.postgresql.ds.PGPoolingDataSource;
/**
* Created by weli on 01/05/2017.
*/
public class PlayWithPGPoolingDataSource {
public static void main(String[] args) throws Exception {
PGPoolingDataSource dataSource = new PGPoolingDataSource();
dataSource.setDataSourceName("jdbc:postgresql://localhost/weli");
dataSource.setUser("weli");
dataSource.setPassword("");
System.out.println(dataSource.getConnection());
}
}
The above code creates a PGPoolingDataSource class instance, and we set relative parameters for the class to connect to the database server. We use the getConnection() method of the dataSource to get the connection from the connection pool. Running the above code could get the following result:
Pooled connection wrapping physical connection org.postgresql.jdbc.PgConnection@497470ed
class com.sun.proxy.$Proxy0
From the above output, we can see a wrapper proxy instance around org.postgresql.jdbc.PgConnection being returned to the user.
From the users perspective, they don’t care about the implementation of the connection instance, they will just use it as an ordinary connection interface and call the methods to operate on the database.
If users call the close method of the connection, it will actually be returned to the connection pool instead of really being closed. This is implemented in the org.postgresql.ds.PGPooledConnection class.
Let’s check the class diagram of the org.postgresql.ds.PGPooledConnection in detail:
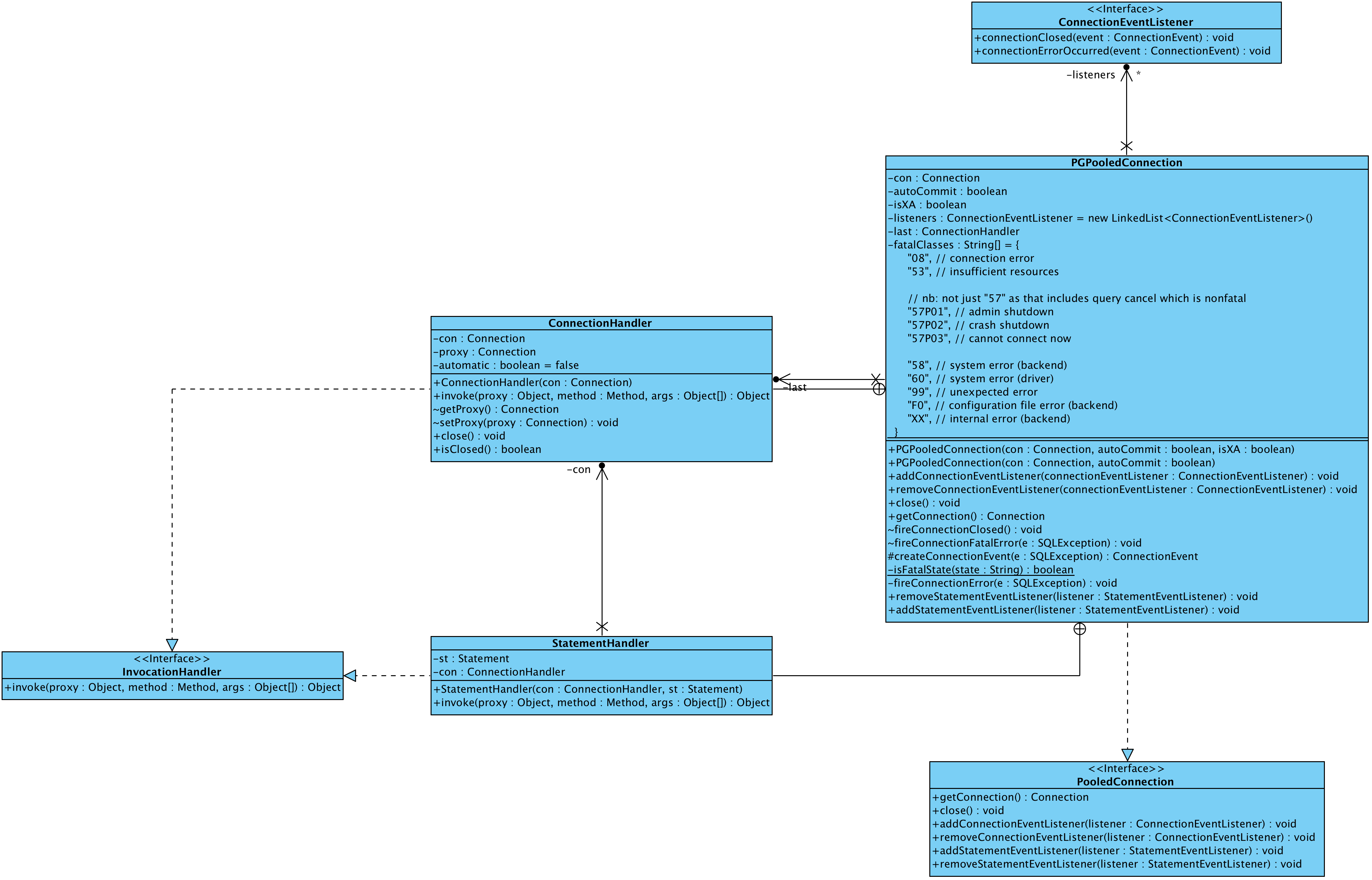
From the above diagram, we can see the connection instanced is proxied, and it is actually the inner class ConnectionHandler inside the org.postgresql.jdbc.ds.PGPooledConnection class.
Here is the debug process screenshot that proves the above conclusion:
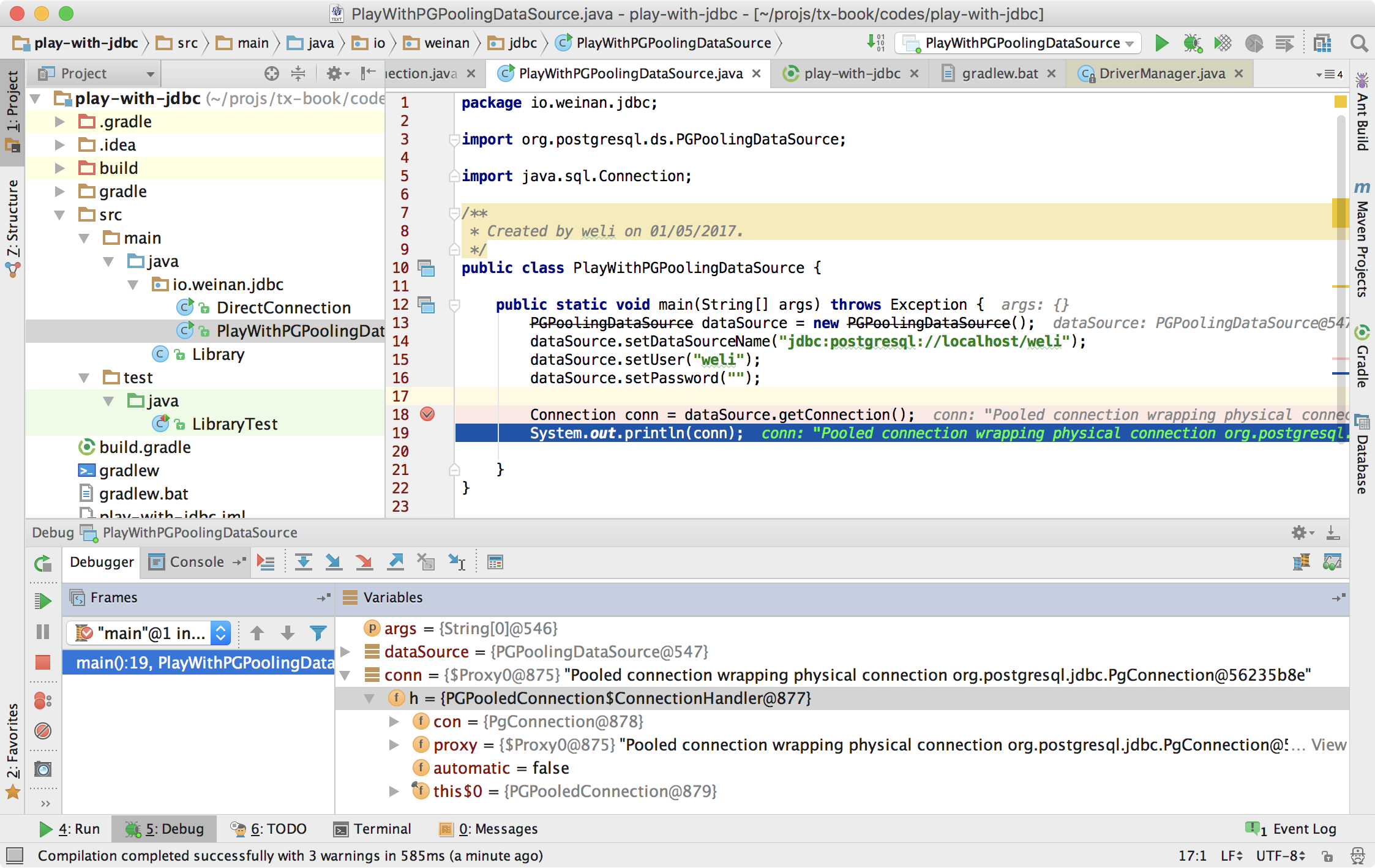
From the above screenshot, you can see I have set the breakpoint at the conn instance returned from the data source. In the inspection window of IntelliJ IDEA, we can see the real class of the conn is PGPooledConnection$ConnectionHandler. Remember that conn has the type of java.sql.Connection, so the users will just treat it as ordinary connection to the database.
The job of PGPooledConnection$ConnectionHandler proxy is to dispatch the calls to the org.postgresql.jdbc.PgConnection that makes physical connections with the database server.
org.postgresql.jdbc.PgConnection is the class that implements the java.sql.Connection interface, and it will make the physical connection with underlying database system.
The org.postgresql.ds.PGPooledConnection$ConnectionHandler proxy will handle the org.postgresql.jdbc.PgConnection. Now let’s check the code of the org.postgresql.ds.PGPoolingDataSource class to see how it manages the lifecycle of the physical connection.
Here is the code of org.postgresql.ds.PGPooledConnection$ConnectionHandler class:
/**
* Instead of declaring a class implementing Connection, which would have to be updated for every
* JDK rev, use a dynamic proxy to handle all calls through the Connection interface. This is the
* part that requires JDK 1.3 or higher, though JDK 1.2 could be supported with a 3rd-party proxy
* package.
*/
private class ConnectionHandler implements InvocationHandler {
private Connection con;
private Connection proxy; // the Connection the client is currently using, which is a proxy
private boolean automatic = false;
public ConnectionHandler(Connection con) {
this.con = con;
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
final String methodName = method.getName();
// From Object
if (method.getDeclaringClass() == Object.class) {
if (methodName.equals("toString")) {
return "Pooled connection wrapping physical connection " + con;
}
if (methodName.equals("equals")) {
return proxy == args[0];
}
if (methodName.equals("hashCode")) {
return System.identityHashCode(proxy);
}
try {
return method.invoke(con, args);
} catch (InvocationTargetException e) {
throw e.getTargetException();
}
}
// All the rest is from the Connection or PGConnection interface
if (methodName.equals("isClosed")) {
return con == null || con.isClosed();
}
if (methodName.equals("close")) {
// we are already closed and a double close
// is not an error.
if (con == null) {
return null;
}
SQLException ex = null;
if (!con.isClosed()) {
if (!isXA && !con.getAutoCommit()) {
try {
con.rollback();
} catch (SQLException e) {
ex = e;
}
}
con.clearWarnings();
}
con = null;
this.proxy = null;
last = null;
fireConnectionClosed();
if (ex != null) {
throw ex;
}
return null;
}
if (con == null || con.isClosed()) {
throw new PSQLException(automatic
? GT.tr(
"Connection has been closed automatically because a new connection was opened for the same PooledConnection or the PooledConnection has been closed.")
: GT.tr("Connection has been closed."), PSQLState.CONNECTION_DOES_NOT_EXIST);
}
// From here on in, we invoke via reflection, catch exceptions,
// and check if they're fatal before rethrowing.
try {
if (methodName.equals("createStatement")) {
Statement st = (Statement) method.invoke(con, args);
return Proxy.newProxyInstance(getClass().getClassLoader(),
new Class[]{Statement.class, org.postgresql.PGStatement.class},
new StatementHandler(this, st));
} else if (methodName.equals("prepareCall")) {
Statement st = (Statement) method.invoke(con, args);
return Proxy.newProxyInstance(getClass().getClassLoader(),
new Class[]{CallableStatement.class, org.postgresql.PGStatement.class},
new StatementHandler(this, st));
} else if (methodName.equals("prepareStatement")) {
Statement st = (Statement) method.invoke(con, args);
return Proxy.newProxyInstance(getClass().getClassLoader(),
new Class[]{PreparedStatement.class, org.postgresql.PGStatement.class},
new StatementHandler(this, st));
} else {
return method.invoke(con, args);
}
} catch (final InvocationTargetException ite) {
final Throwable te = ite.getTargetException();
if (te instanceof SQLException) {
fireConnectionError((SQLException) te); // Tell listeners about exception if it's fatal
}
throw te;
}
}
Connection getProxy() {
return proxy;
}
void setProxy(Connection proxy) {
this.proxy = proxy;
}
public void close() {
if (con != null) {
automatic = true;
}
con = null;
proxy = null;
// No close event fired here: see JDBC 2.0 Optional Package spec section 6.3
}
public boolean isClosed() {
return con == null;
}
}
From the above code, we can see the invoke(...) method in the ConnectionHandler wraps around the Method of Connection. For example, it handles the event like connection close. Here is the relative code:
fireConnectionClosed();
Now let’s check the code of this fireConnectionClosed() method:
/**
* Used to fire a connection closed event to all listeners.
*/
void fireConnectionClosed() {
ConnectionEvent evt = null;
// Copy the listener list so the listener can remove itself during this method call
ConnectionEventListener[] local =
listeners.toArray(new ConnectionEventListener[listeners.size()]);
for (ConnectionEventListener listener : local) {
if (evt == null) {
evt = createConnectionEvent(null);
}
listener.connectionClosed(evt);
}
}
From the above code, we can see the fireConnectionClosed() method will create an instance of ConnectionEvent class and register it into an instance of ConnectionEventListener, and finally the listener will fire the connectionClosed(...) event.
The ConnectionEvent and ConnectionEventListener are two interfaces provided by the JDBC specification, and it is the container’s job to implement them properly to handle the event in a pooling environment. For example, in the PGPoolingDataSource demo datasource implementation, it will just return the connection back to its pool instead of really closing it. In the real container like Wildfly, it will rely on its pooling provider to manage the events (Apache Commons DBCP is a popular connection pooling provider used by many application servers). We will check the detail of the PGPoolingDataSource later in the article.
Now let’s see the class diagram of the javax.sql.ConnectionEvent and javax.sql.ConnectionEventListener interfaces:

From the above diagram, we can see the main job of the ConnectionEventListener interface is to handle the connectionClosed(...) method, and the ConnectionEvent will be passed in as the context. Now we need to check the implementation of the PGPoolingDataSource to see how to implement a pooling data source.
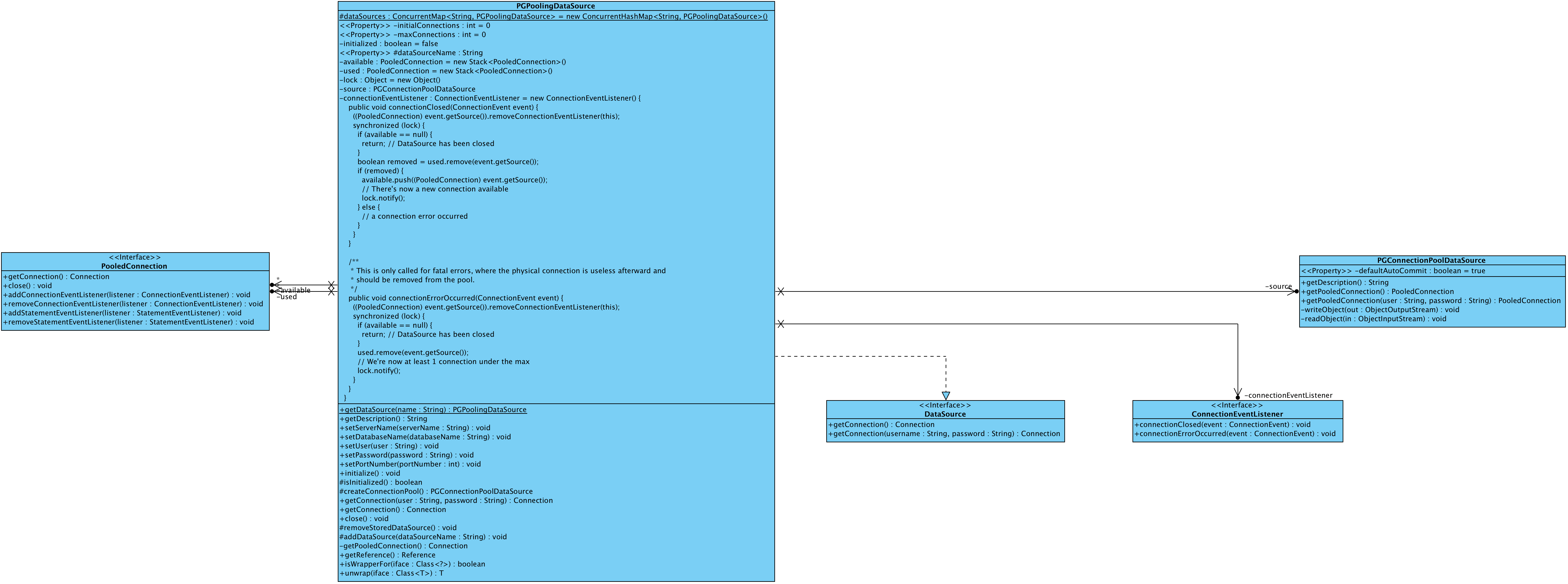
The above org.postgresql.ds.PGPoolingDataSource is a demo class that implements a simple data source pool. Firstly let’s check how does it stores connections in a “pool”. Here are the relative data structures in the class:
private Stack<PooledConnection> available = new Stack();
private Stack<PooledConnection> used = new Stack();
From the above code, we can see there are two stacks to store its “pooled” connections: one is named available and the other is called used. Besides the above two stacks, the PGPoolingDataSource class also stores a PGConnectionPoolDataSource instance:
private PGConnectionPoolDataSource source;
From the above code, we can see an instance of PGConnectionPoolDataSource that implements the javax.sql.ConnectionPoolDataSource interface is stored. Let’s now review the usages of ConnectionPoolDataSource interface: it defines a getPooledConnection() that will be used to return a javax.sql.PooledConnection, and the javax.sql.PooledConnection will return a managed Connection instance from the pool. In PostgreSQL driver, the org.postgresql.ds.PGPooledConnection implements the javax.sql.PooledConnection interface, and will return a ConnectionHandler proxy class that wraps around the physical org.postgresql.jdbc.PgConnection instance.
Next, the ConnectionHandler proxy will wrap the connection methods with event listener, and the event listener will be handled properly by the pooling vendor. Our pooling vendor is PGPoolingDataSource, which is a demo class to show how to implement a data source pool.
Now let’s go back to PGPoolingDataSource to see how it initializes the data source. Here is the initialize() method in the class:
/**
* Initializes this DataSource. If the initialConnections is greater than zero, that number of
* connections will be created. After this method is called, the DataSource properties cannot be
* changed. If you do not call this explicitly, it will be called the first time you get a
* connection from the DataSource.
*
* @throws SQLException Occurs when the initialConnections is greater than zero, but the
* DataSource is not able to create enough physical connections.
*/
public void initialize() throws SQLException {
synchronized (lock) {
source = createConnectionPool();
try {
source.initializeFrom(this);
} catch (Exception e) {
throw new PSQLException(GT.tr("Failed to setup DataSource."), PSQLState.UNEXPECTED_ERROR,
e);
}
while (available.size() < initialConnections) {
available.push(source.getPooledConnection());
}
initialized = true;
}
}
The above code shows some important tasks that initialize() method will perform. Firstly, it will create a PGConnectionPoolDataSource instance. Here is the code:
source = createConnectionPool();
The above code will create an instance of the PGConnectionPoolDataSource. The data source will be used to create some idle connections and pushed into the available stack. Here is the code:
while (available.size() < initialConnections) {
available.push(source.getPooledConnection());
}
From the above code, we can see some connections are created initially and pushed to the available stack. This is a cache scheme for demonstration. Now we should check how does the connections are fetched from the stack. Here is the getPooledConnection() method that takes the task:
private Connection getPooledConnection() throws SQLException {
PooledConnection pc = null;
Object var2 = this.lock;
synchronized(this.lock) {
if(this.available == null) {
throw new PSQLException(GT.tr("DataSource has been closed.", new Object[0]), PSQLState.CONNECTION_DOES_NOT_EXIST);
}
while(true) {
if(!this.available.isEmpty()) {
pc = (PooledConnection)this.available.pop();
this.used.push(pc);
break;
} else if(this.maxConnections != 0 && this.used.size() >= this.maxConnections) {
try {
this.lock.wait(1000L);
} catch (InterruptedException var5) {
;
}
} else {
pc = this.source.getPooledConnection();
this.used.push(pc);
break;
}
}
}
pc.addConnectionEventListener(this.connectionEventListener);
return pc.getConnection();
}
The above method shows us how does a connection fetched from the stack. Here is the relative part of the code:
pc = (PooledConnection)this.available.pop();
this.used.push(pc);
From the above code we can see there will be a connection poped from the available stack, and it will be pushed it into the used stack. Finally the connection will be returned to the caller. If maxConnections are reached, it means there is no usable connection in the available stack. In this condition, the process will wait for for 1 second for the available connections to be returned back to the stack and try again:
else if(this.maxConnections != 0 && this.used.size() >= this.maxConnections) {
...
this.lock.wait(1000L);
...
}
The above logic is very low efficient, that’s why this PGPoolingDataSource class is just for demonstration and can’t be used in production field. In application server, we’ll have more powerful connection pool solutions.
Now let’s go on our code reading. If the number of connections in the available stack does not meet the maxConnections, it will create a new connection from the data source and immediately pushed into used stack:
...
pc = this.source.getPooledConnection();
this.used.push(pc);
...
The above code shows the new connection is created and pushed into the used stack. Now we know if the connection is being used by a thread, it will be kept into the used stack.
Now let’s think about this question: how does the connection moved from used stack back to available stack? The answer is: this is achieved by the listener pattern. In getPooledConnection() method, we can see a event listener is added to the pooled connection. The code is like this:
pc.addConnectionEventListener(this.connectionEventListener);
From the above code, we can see the connectionEventListerner instance is added into the PooledConnection pc instance. The connection listener will finally be called with its connectionClosed(...) method, and the method is actually implemented by the pooling provider. So it is job of the PGPoolingDataSource demo class to implement the logic itself. Here is how the ConnectionEventListener inner class in PGPoolingDataSource class that implements it for demonstration purpose:
/**
* Notified when a pooled connection is closed, or a fatal error occurs on a pooled connection.
* This is the only way connections are marked as unused.
*/
private ConnectionEventListener connectionEventListener = new ConnectionEventListener() {
public void connectionClosed(ConnectionEvent event) {
((PooledConnection) event.getSource()).removeConnectionEventListener(this);
synchronized (lock) {
if (available == null) {
return; // DataSource has been closed
}
boolean removed = used.remove(event.getSource());
if (removed) {
available.push((PooledConnection) event.getSource());
// There's now a new connection available
lock.notify();
} else {
// a connection error occurred
}
}
}
/**
* This is only called for fatal errors, where the physical connection is useless afterward and
* should be removed from the pool.
*/
public void connectionErrorOccurred(ConnectionEvent event) {
((PooledConnection) event.getSource()).removeConnectionEventListener(this);
synchronized (lock) {
if (available == null) {
return; // DataSource has been closed
}
used.remove(event.getSource());
// We're now at least 1 connection under the max
lock.notify();
}
}
};
From the above code, we can see that when a pooled connection is closed, it will be returned back to the available pool and removed from used pool. The connection won’t be really closed actually.
Now let’s see how does org.postgresql.ds.PGPooledConnection class call the above implemented listener. Here is the code:
private final List<ConnectionEventListener> listeners = new LinkedList<ConnectionEventListener>();
...
/**
* Adds a listener for close or fatal error events on the connection handed out to a client.
*/
public void addConnectionEventListener(ConnectionEventListener connectionEventListener) {
listeners.add(connectionEventListener);
}
/**
* Removes a listener for close or fatal error events on the connection handed out to a client.
*/
public void removeConnectionEventListener(ConnectionEventListener connectionEventListener) {
listeners.remove(connectionEventListener);
}
...
/**
* Used to fire a connection closed event to all listeners.
*/
void fireConnectionClosed() {
ConnectionEvent evt = null;
// Copy the listener list so the listener can remove itself during this method call
ConnectionEventListener[] local =
listeners.toArray(new ConnectionEventListener[listeners.size()]);
for (ConnectionEventListener listener : local) {
if (evt == null) {
evt = createConnectionEvent(null);
}
listener.connectionClosed(evt);
}
}
/**
* Used to fire a connection error event to all listeners.
*/
void fireConnectionFatalError(SQLException e) {
ConnectionEvent evt = null;
// Copy the listener list so the listener can remove itself during this method call
ConnectionEventListener[] local =
listeners.toArray(new ConnectionEventListener[listeners.size()]);
for (ConnectionEventListener listener : local) {
if (evt == null) {
evt = createConnectionEvent(e);
}
listener.connectionErrorOccurred(evt);
}
}
...
From the above code, we can see the listeners are stored in listeners linked list. These methods will be called in the inner class ConnectionHandler, which is the proxy class represents the connection as we have seen. We can see the fireConnectionClosed() is called when the user invoke the close() method of the connection.
From user’s perspective, they don’t need to care about these underlying implementations, and they just use the connection interface as common to interact with the underlying database. From the database manager’s perspective, they can change or tune the data pooling provider in the application server level. In our example, we use a very simple data pooling provider named PGPoolingDataSource. We even don’t have to implement a pool at all and just provide a single connection to the users. For example, there is a ‘PGSimpleDataSource’ class provided by PostgreSQL driver that will not provide any ‘pooling’, and it will just pass every connection request to the underlying physical connections. Here is the code of the class:
package org.postgresql.ds;
import org.postgresql.ds.common.BaseDataSource;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.sql.SQLException;
import javax.sql.DataSource;
/**
* Simple DataSource which does not perform connection pooling. In order to use the DataSource, you
* must set the property databaseName. The settings for serverName, portNumber, user, and password
* are optional. Note: these properties are declared in the superclass.
*
* @author Aaron Mulder (ammulder@chariotsolutions.com)
*/
public class PGSimpleDataSource extends BaseDataSource implements DataSource, Serializable {
...
}
From the above code, we can see the PGSimpleDataSource is just a thin layer that didn’t provide any data source pool inside. In this article, I have showed you the JDBC connection pool design, and we have checked a demo implementation of the architecture. We can see the whole design is very flexible, it decouples three kind of people: the user of the data base, the data base driver developer, the connection pool provider. We haven’t checked the real connection pool provider in an application server. For example, Wildfly uses Apache Commons DBCP as its connection pool provider.
I plan to write article to introduce the data source in Wildfly, but it will be out of the scope of this series of the articles. In the next article, I’d like to introduce the transaction aspect of the JDBC specification.