关于并发编程的一些思考(二)
这篇文章介绍三种non-block的并发级别:Sequential Consistency,Quiescent Consistency和Serializability。
在「herlihy2011art」1一书当中,作者给出了三种non-blocking的并发级别,分别是Sequential Consistency,Quiescent Consistency,Serializability。这篇文章里给大家讲解一下书里面介绍的这三种并发级别各自的要求。
首先我们先看Sequential Consistency,在书中这个是作者介绍的第二个并发级别,但是理解这个级别最为重要,所以我们先看这个级别。书中对Sequential Consistency的定义如下:
Principle 3.4.1. Method calls should appear to take effect in program order.
简单来讲,Sequential Consistency就是保证一件事情:同一个thread下程序的执行顺序不能乱。这个要求具体的含义可以通过例子来展示。我们来看下面这个程序的执行过程:

(图片来自「herlihy2011art」)
上面这条虚线,我们可以理解为一个单线程的程序的执行过程。那么上面的程序执行过程对应代码大概是这样的:
q.enq(x) -> q.deq(y)
如上所示,就是就是往队列q里面通过enq方法,也就是enqueue,加入数据x,然后从队列q里面deq(y),就是dequeue,取得的结果是y。Queue,也就是队列,是一种”先入先出”(First-In-First-Out, FIFO)的数据结构,所以上面的这个q里面就是先有了数据y,然后加入了数据x,取数据的时候,就会先取到y,再取到x。而Sequential Consistency这个并发级别,保证在一条线上,也就是一个thread内的代码执行先后顺序不会被打乱。也就是说,上面这样的代码,要保证q.enq(x)先执行完成,q.deq(y)要后执行完成。
大家可能觉得这个要求不是所有的操作系统都保证了吗,我们写一个代码,程序肯定是一行一行往下执行的啊。但实际情况远比想象的复杂,如果我们写C语言的代码,那么现代的编译器在编译的时候是有可能会打乱代码的执行顺序的,而编译器reorder codes的目的是针对CPU的流水线架构2做优化,使得代码执行效率更高。
一般现代的编译器在reorder这块都会对代码的功能判断的很准确,所以不会造成程序的逻辑错误,比如上面的两个操作,编译器是不会把它们reorder的。但是对于multi-threaded的程序,情况就复杂的多了。编译器很可能错误做一个它认为一个安全的codes reorder,但在多线程的环境下造成程序的逻辑错误。所以对于多线程的代码,我们最好不要打开编译器的允许codes reorder级别的优化选项。我们可以看下图中这个双线程程序的执行过程:
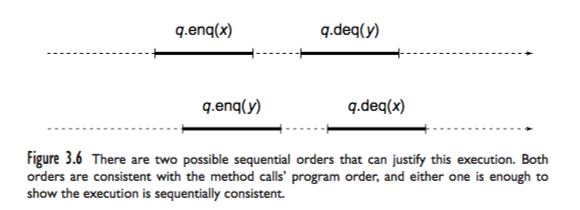
(图片来自「herlihy2011art」)
如上图所示,这是两个threads在公用一个队列q的情况。其中,上面那条thread的程序执行过程是:
q.enq(x) -> q.deq(y)
下面那条thread的代码是:
q.enq(y) -> q.deq(x)
如果虚线是时间线,代表时间顺序,那么两条threads合并后对队列q的操作顺序就是:
q.enq(x) -> q.enq(y) -> q.deq(y) -> q.deq(x)
因为queue是First In First Out的数据结构,所以上面的程序的执行过程在逻辑上是错误的。因为首先是x进入q,然后是y进入q,然后从q里面取出的第一个数据是y,而不是x,这就不是先入先出的顺序了,与queue的数据结构定义矛盾。如果想让上面的执行过程在逻辑上正确,可以这样解释:q.enq(x)虽然在第一条thread里面先执行起来,但是第二条thread上后执行起来的q.enq(y)却先执行完成了。这样,q里面先进入的数据其实是y,而不是x。
这样破坏了Sequential Consistency吗?并没有,因为Sequential Consistency保证的是同一个thread里面代码的执行顺序不可以被打乱,但不保证multi-threads之间的代码的执行顺序。在操作系统的设计上,process scheduler也是这样做的,操作系统可以调整各个的threads的执行顺序,可以让先执行的thread休息一会,让后执行的thread跑一会,这个是现代多任务操作系统的基本功能。
所以我们要想协调各个threads的执行顺序,需要加锁,Sequential Consistency这个级别的并发要求是不保证multi-threads之间的代码执行顺序的。可以看出来,Sequential Consistency其实是一种比较弱的同步要求,而且它的要求不需要加锁,它是一个non-blocking的并发要求。
接下来我们看看下面这两个threads的程序执行过程:
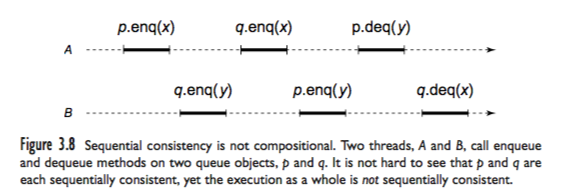
(图片来自「herlihy2011art」)
上面这个双线程的程序,其实就是对两个队列p、q的操作。对p的操作,按照时间顺序是这样的:
p.enq(x) -> p.enq(y) -> p.deq(y)
我们上篇文章讲过,队列是先入先出的数据结构,所以上面的代码逻辑要想成立,就需要p.enq(y)先执行。因为Sequential Consistency不允许一个线程内的代码顺序被打乱,但可以不同线程之间的代码顺序打乱,而p.enq(x)和p.enq(y)是在两个不同的线程上,所以,后启动的p.enq(y)可以先执行,这样,逻辑就可以成立,而实际的执行顺序就变成了:
p.enq(y) -> p.enq(x) -> p.deq(y)
接下来,我们看两个线程对q的操作:
q.enq(y) -> q.enq(x) -> q.deq(y)
这个代码逻辑没什么问题,看来q.enq(y)就是先启动,并且先执行了。接下来我们要看上面代码的整体逻辑了。我们看上面的图,它的这个执行过程是sequential consistent的吗?刚才分析了,要保证p这边的操作逻辑正确,那么p.enq(x)要在p.enq(y)后面执行,因此这里确定了执行顺序是:
p.enq(y) -> p.enq(x)
看第一条thread,p.enq(y)的前面是q.enq(y),因此q.enq(y)肯定要比p.enq(y)先执行,因为这是一个线程内部,不可以打乱程序执行顺序。到目前为止,确定下来的执行顺序就是:
q.enq(y) -> p.enq(y) -> p.enq(x)
再看第二条thread,p.enq(x)后面是q.enq(x),因为是一个线程内部,所以必须是p.enq(x)先执行,q.enq(x)后执行。因此,确定下来的整体执行顺序就是:
q.enq(y) -> p.enq(y) -> p.enq(x) -> q.enq(x)
我们从上面确定下来的顺序里发现了什么?就是对q的操作顺序:
q.enq(y) -> q.enq(x)
但是我们最后对q的deq操作,得到的是x:
q.enq(y) -> q.enq(x) -> q.deq(x)
这很显然是不符合q的first-in-first-out性质,自相矛盾了。
因此,在不改变一个线程内部的代码执行顺序的前提下,上面这张图里的代码执行过程是自相矛盾的。
我们通过反证法证明了所以上面这个双线程的程序执行过程不满足sequential consistency的要求。
这是一个很有意思的分析过程:我们把p或者q的操作过程各自单独拿出来看,都是可以满足sequential consistency的,但是如果我们把对两个队列操作合并到一起,就会发现在时间线上,因为p的内在执行逻辑,导致q这里有了一个确定的执行过程,而这个过程与sequential consistency的要求矛盾。
因此我们说,sequential consistency不是compositional的。也就是说,两个sequential consistent的过程,合并到一起后,不一定还是sequential consistent的。书里做出的说明如下:
Sequential consistency is not compositional.
理解了sequential consistency,接下来就可以进一步理解serializability。为了解决sequential consistency不是compositional的问题,serializability在sequential consistency的基础上加了一条要求:
Principle 3.5.1. Each method call should appear to take effect instantaneously at some moment between its invocation and response.
也就是说,serializability要求程序执行的“原子性”,每一个call应该是瞬间完成的。我们回过头来再来看这张图:
(图片来自「herlihy2011art」)
上面这张图是我们在讨论sequential consistency的时候用到的一个双线程的程序执行过程图。我们可以看到这个图里面把enq和deq的calls都标记成了一段时间,也就是说,每一个call都是需要一定长度的时间来完成,而不是一瞬间完成的,因此,thread 2上面的q.enq(y)可能被操作系统的process scheduler给提到thread 1上面的q.enq(x)之前完成。
但是serializability就要求这种情况不能发生,因为所有的call在serializability的要求下,要被看成是一个点,而不是一条线,那么我们上面的图中的四个call就不是4条线而是4个点。因此q.enq先执行起来一定是先完成的,因为执行即完成,每一个call都是一个原子。所以在serializability的要求下,上面的程序的执行过程就必须是:
q.enq(x) -> q.enq(y) -> q.deq(y) -> q.deq(x)。
当然我们知道这个执行顺序有逻辑错误,因为q是先入先出的数据结构,因此我们可以说上面的程序过程不满足serializability的要求,但是满足sequential consistency的要求。也就是说serializability是比sequential consistency在同步性上要求更高的。
此外,serializability是compositional的,具体的证明过程不在这篇文章里详细展开了,大家可以自己再看书学习证明过程。
最后简单说一下quiescent consistency,这个同步要求比sequential consistency和serializability都要弱,因为它允许同一条thread内的代码执行顺序被打乱,在这个条件下,基本上已经没有什么同步性可言,对大家的实际使用价值可能不大。总结一下就是:
serializability的同步要求 > sequential consistency的同步要求 > quiescent consistency的同步要求。
你可能会在网上看到一些文章说quiescent consistency的同步要求要高于sequential consistency,实际这是错的。quiescent consistency在允许同一条thread的程序顺序被打乱的情况下,同步要求肯定是要弱于sequential consistency的,本书的作者也强调了这一点。
这三种并发要求都不需要锁,都是non-blocking的,都是比较弱的同步要求,但是理解non-blocking的并发模型实际上非常重要,因为加锁的blocking模型其实都比较简单了,效率也不高,很多时候我们需要知道什么时候我们可以不加锁,理解nonblocking领域的并发级别,可以帮助我们更好地理解自身使用场景的需求,写出更高效的代码。