Eval,Macro,Preprocessor,Homoiconicity(下)
在下篇里面,重点展开讲一下Clojure的syntax设计。
下图是类C语言的编译过程:
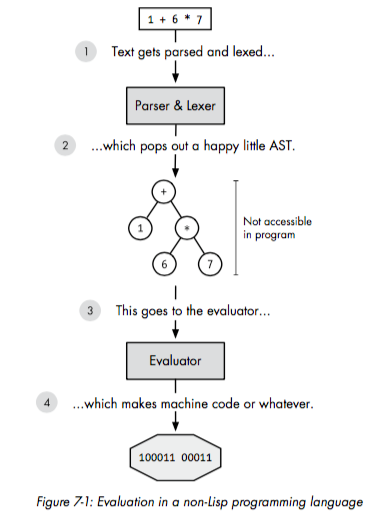
「本图片和后续两张图片来自Higginbotham, Daniel. Clojure for the Brave and True: Learn the Ultimate Language and Become a Better Programmer. No Starch Press, 2015.」
如上所示,大部分编程语言的syntax本身需要被Lexer和Parser给转化成树形结构,也就是AST,这个过程就是编译器的前端要做的事情。而Clojure本身的syntax就是树形结构,因此不需要转化过程,如下图所示:
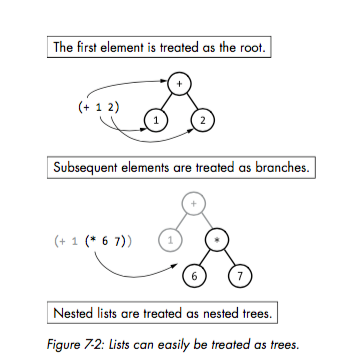
也就是说,Clojure代码结构本身就是其它语言转化成AST的结构,因此code is data,data is code。这样一来,macro就可以自由改变这个树形结构。比如上一篇中给出的例子:
(list (second infixed) (first infixed) (last infixed))
上面这段代码体现出了code is data的特点:我们可以在macro中修改传入的list里面的元素位置,实际上就是调整树形结构。
因此,Clojure(或者说lisp系语言)的Lexer和Parser就简化成了Reader:
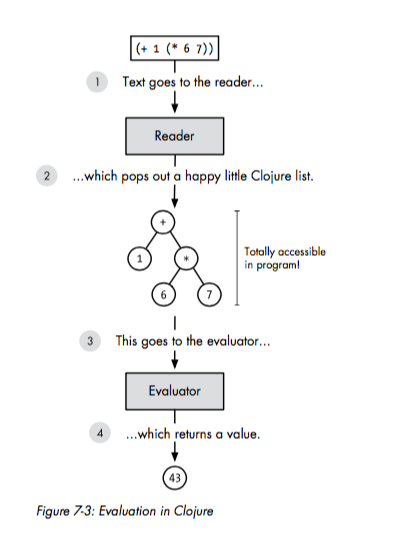
没有了「代码 -> AST」的转化过程,只需要Reader就可以完成代码的读入和树形结构的建立了。
接下来简单说一句「Laziness」。这个语言特性不是Haskell的专利,在Clojure里面也有实现,比如Clojure里面的「Lazy seq」。关于这个「Lazy seq」,后续单开文章来讲解。