just-in-time compiler的实现原理
所谓just-in-time compiler,就是指程序在运行的时候,直接把「源代码」转化(编译)成「机器码」(或者表现为汇编代码),然后把编译后的代码直接执行起来。
比如:Java的虚拟机在运行bytecode的时候,把bytecode在运行时直接编译成机器码,这样在操作系统的层面运行,而不是在虚拟机的层面运行,从而提高运行效率。
其实不管jit的表现形式是怎样的,最后的本质一定是:
- 在「runtime」期间,直接往「process的内存空间」注入「机器码」并执行代码。
因此到最后,实现方式一定是:
- 在当前process里面划分出一片内存空间。
- 将划分出来的内存空间标记为「可执行」。
- 将运行时动态产生的机器码直接写入划分的内存空间。
- 将「PC寄存器」(程序指针)指向上面产生的代码的起始位置。
- 执行动态产生的代码。
- 根据实际需求,销毁或保留上面申请到的内存空间。
上面的环节当中,核心就是申请内存空间,并标记为「可执行」。这里面要调用到几个kernel的system call。其中,运行时动态申请内存要用到mmap():
mmap(NULL, PAGE_SIZE, prot, flags, -1, 0)
运行时动态转变内存的Read/Write/Executable属性,要用到mprotect():
mprotect(buf, PAGE_SIZE, PROT_READ | PROT_EXEC);
动态往设置好的内存空间注入机器码,需要具备把汇编代码转成机器码的能力(手写或者用process内嵌的just-in-time compiler自动编译)。比如下面是一个手写的,把四则运算转成机器码的逻辑(注释里是机器码对应的汇编代码):
switch (operator) {
case '+':
asmbuf_ins(buf, 3, 0x4801f8); // add %rdi, %rax
break;
case '-':
asmbuf_ins(buf, 3, 0x4829f8); // sub %rdi, %rax
break;
case '*':
asmbuf_ins(buf, 4, 0x480fafc7); // imul %rdi, %rax
break;
case '/':
asmbuf_ins(buf, 3, 0x4831d2); // xor %rdx, %rdx
asmbuf_ins(buf, 3, 0x48f7ff); // idiv %rdi
break;
}
上面的代码中,直接把机器码用16进制数字的形式,通过asmbuf_ins函数注入到了buf(申请的内存)里面。这个asmbuf_ins:
void asmbuf_ins(struct asmbuf *buf, int size, uint64_t ins) {
for (int i = size - 1; i >= 0; i--)
buf->code[buf->fill++] = (ins >> (i * 8)) & 0xff;
}
动态分配了内存并生成了代码以后,我们就可以在process内部运行动态生成的代码了。运行代码其实是比较复杂的一个地方。因为是汇编代码,这里要用到各个操作系统和cpu架构相关的calling convention。比如x86架构的convention:
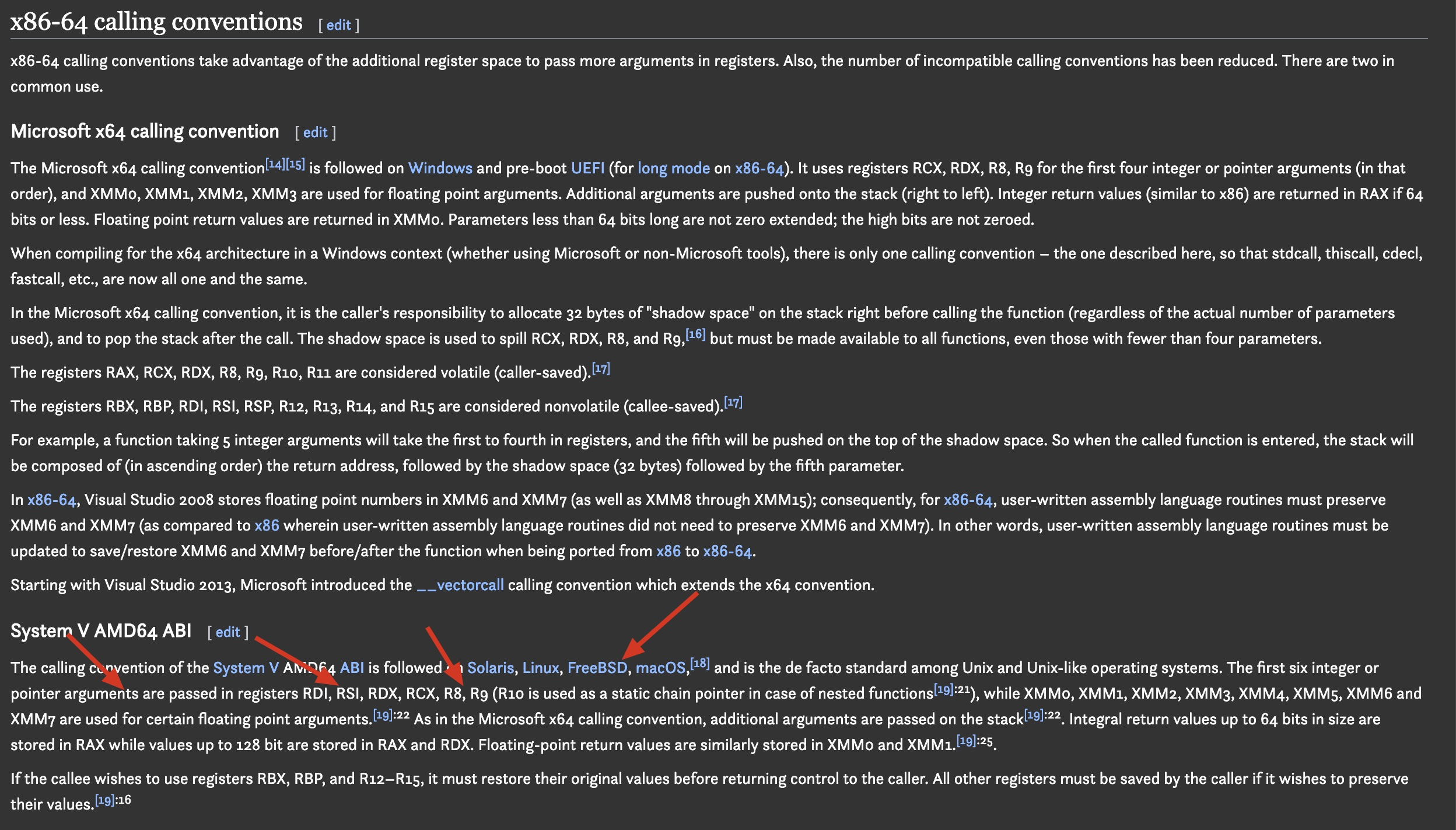
从文档中可以看到,按照特定架构的要求,准备好寄存器,就可以进行代码的calling。
__attribute__ ((sysv_abi))
long (*recurrence)(double *, long) = (void *)buf->code;
其中buf里面的code就是上面手工注入的,并且按照calling convention来准备好的机器码。这样recurrence就变成了函数的指针,但实际上它的实现是我们动态注入的机器码。准备好函数的指针,就可以用它来call函数了:
recurrence(stack, max_backreference);
以上就是实现一个最基础的just-in-time compiler的全过程。上面的代码的完整实现在这里:
- https://gist.github.com/anonymous/f7e4a5086a2b0acc83aa
上面代码对应的文章在这里:
可以仔细读一下,对kernel,汇编,架构的理解会有很大提升。
- 上一篇 图数据库学习资料的整理
- 下一篇 tinkerpop的使用(上)