使用selenium-webdriver的docker容器做页面爬取
Selenium提供了预装好webdriver的容器供爬取页面使用:
它对应的github项目在这里:
可以仔细阅读一下项目文档,学习使用方法:
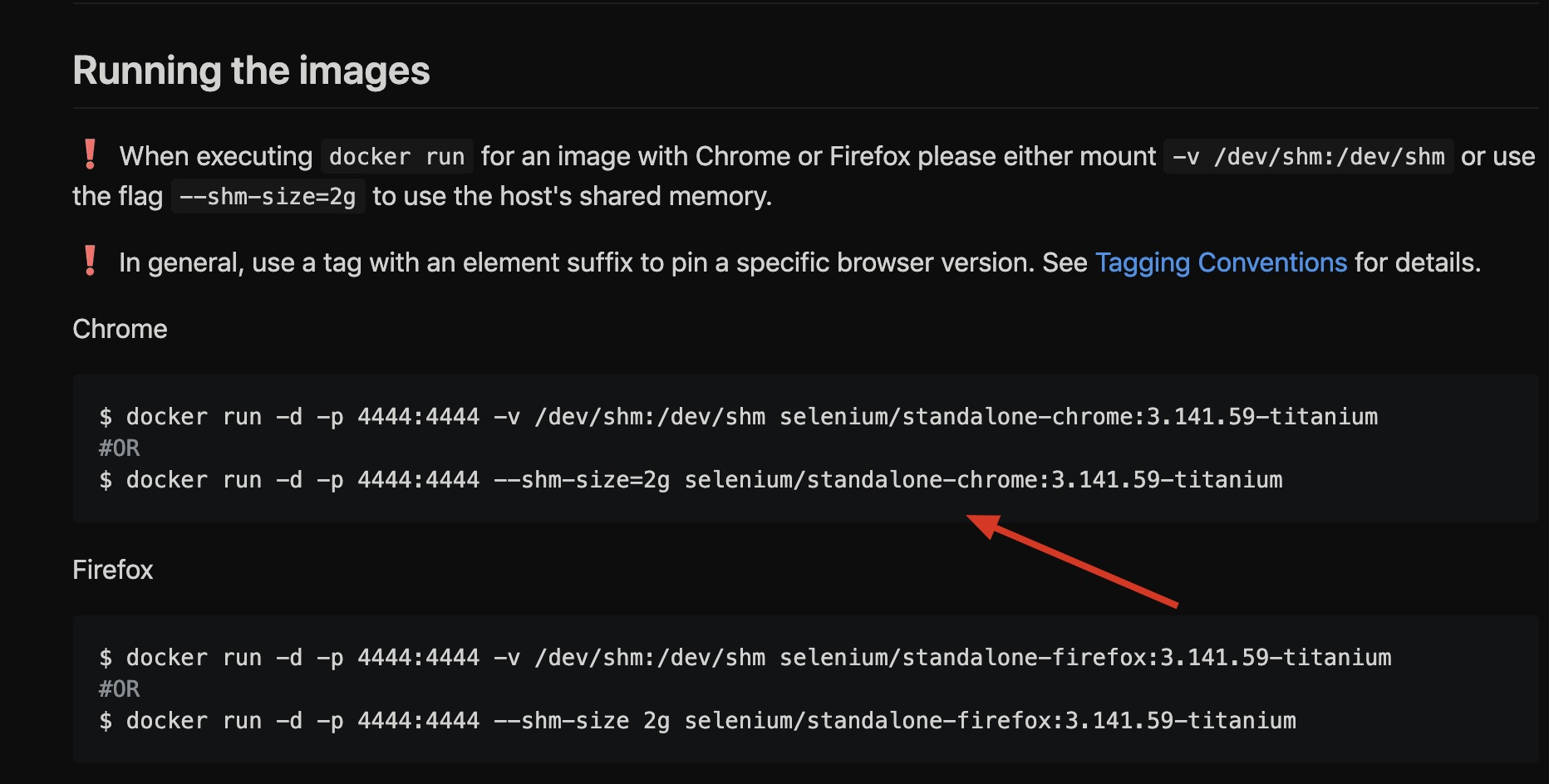
运行命令下载并启动容器:
$ docker run -d -p 4444:4444 --shm-size=2g selenium/standalone-chrome:3.141.59-titanium
看到容器启动了:
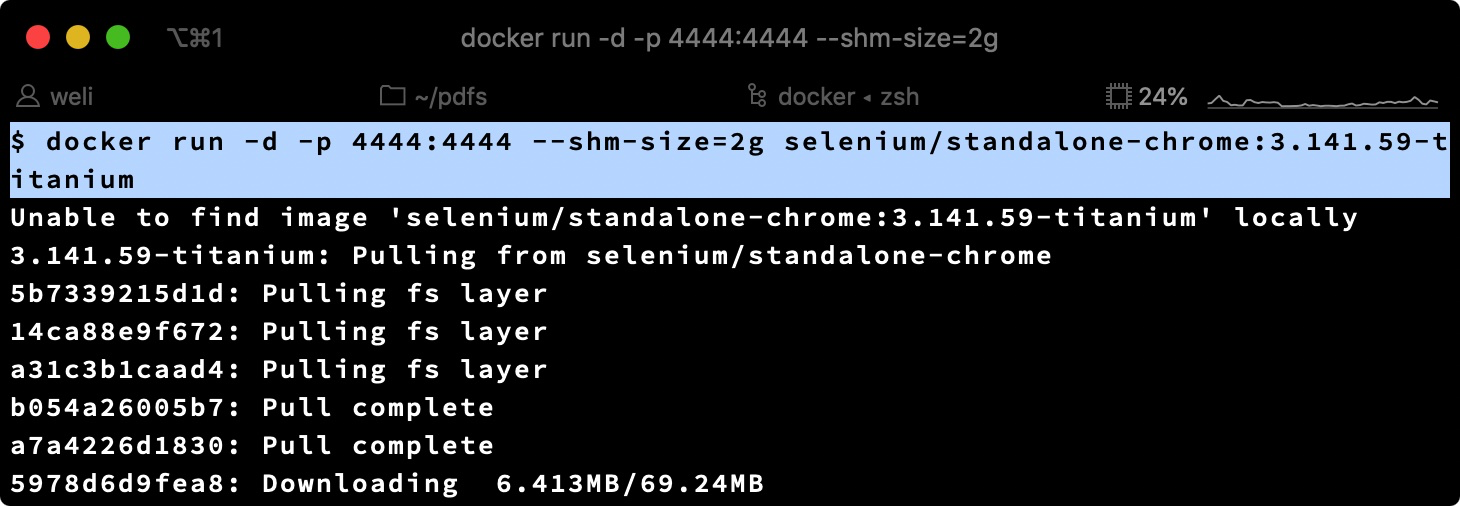
验证一下4444端口可以连接了:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
96c58ae9cd4b selenium/standalone-chrome:3.141.59-titanium "/opt/bin/entry_poin…" 26 seconds ago Up 25 seconds 0.0.0.0:4444->4444/tcp cranky_ramanujan
$ telnet localhost 4444
Trying ::1...
Connected to localhost.
Escape character is '^]'.
爬虫代码:
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.chrome.options import Options
import time
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444/wd/hub',
desired_capabilities=DesiredCapabilities.CHROME)
driver.get('http://pythonscraping.com/pages/javascript/ajaxDemo.html')
time.sleep(3)
print(driver.find_element_by_id('content').text)
driver.close()
代码来源和相关文档:
上面的代码里有几点需要注意:
headless模式是让容器里的chrome浏览器使用不启动图形界面运行,因为容器里没发使用图形界面,我们只需要调用浏览器的引擎,访问页面。- 我们的代码连接容器的
4444端口,就是webdriver的侦听端口。webdriver会去和Chrome浏览器打交道。 - 我们使用的容器是
CHROME浏览器类型的,selenium还提供基于Firefox浏览器的容器,按照需要使用即可。
运行代码,成功爬取页面:
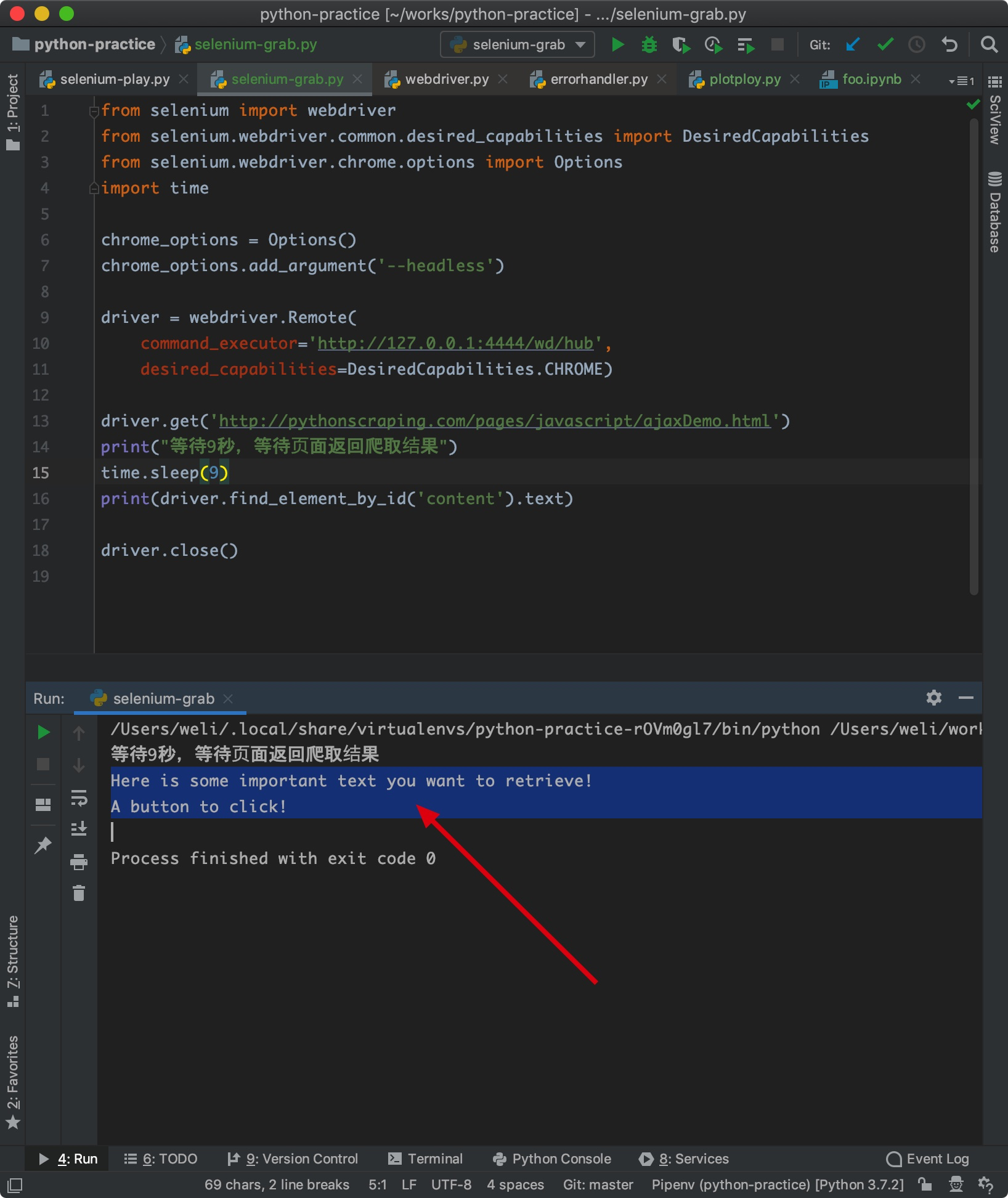
如上所示,得到爬取结果。这个项目的源代码我放在这里了:
有需要自取。