关于并发编程的一些思考(一)
(这个系列的文章也是旧文,慢慢整理到博客当中。)
梳理学习的脉络,给大家讲讲atomicity,lock,consistency三个概念和它们背后的世界。
我们已经在一个并行计算的世界里面了:我们的CPU是多核的,我们的操作系统是多任务操作系统,我们生活在网络时代,网络群集部署是并发的自然应用。所有和并发相关的领域,重要性都会越来越加强,所以把并发这块学好也是很重要的。
并发编程涉及到三个大的问题:
- 如何把一个整块的工作划分成小块并行执行
- 如何协调工作彼此不冲突
- 如何保证整个过程的可靠性
实际上并发编程是非常有趣的,因为它贴近我们日常生活中的很多场景,在学习过程中,我们就可以感受到。
为了实现协同工作,我们要用到很多技术。比如,如果多个worker要同时访问一个资源,那么必然要有先后顺序。如何协调这种顺序呢?这里面就引申出很多的标准化的概念,用于描述各种可能的场景,比如Quiescent Consistency,Sequential Consistency,Linearizability。
此外,一个worker在使用一个资源的时候,如何保证其它worker不动这个资源?也就是说,如何保护这个资源?这就涉及到了Lock(锁)的概念。但是锁本身该如何实现?这里面要有很多比较艰难的学习过程。
还有更复杂的情况,可能一个worker要做3件事情,要保证这三件事情要么同时成功,只要有一件事情失败,那么整个3件事情要全部算做失败,回到初始状态。这里面就有了Transaction(事务)的概念。
这些加在一起,就是并发编程的研究领域了,里面涉及到的理论模型,算法,实际应用。后续的文章会讲这些内容。
大家觉得并发编程学习起来很难,其实这块主要是知识体系比较庞大,设计比较多,理论学习比较漫长,找到一个学习的脉络,学习起来就不难。
首先我们要明白并发编程要解决什么问题。所谓「并发」,本质上就是指,同时有多个worker在工作,这些workers可能在做同一个task,也可能在做不同的task。此外,如果是多个tasks,那么这些tasks,可能相互之间有关联,也可能没有关联。
那么我们把上面所说的场景详细划分一下。首先是最简单的,一个worker,一个task,这种就谈不上「并发」了,就是一个线性的一个人的独立工作。这个就没什么可讲的。
接下来是多个workers,做多个tasks,但是多个tasks之间毫无关联,这个也没什么可讲的,就相当于各个worker做各自手里毫不相关的task,一个个都是孤岛,那么也和之前一个worker,一个task本质上是一样的。就算是每个worker手里有多个tasks,如果worker手里的task互相不相关,那也是一样的情况。
最后一种情况是我们要考虑的,其实是两种情况,就是多个workers对应一个task,或者对应多个tasks,但是多个tasks之间有关联性。
这两种情况涉及到两个问题:第一个问题,多个workers之间如何协调执行顺序?如果执行顺序错误,很可能任务失败,这里面涉及到任务本身的逻辑。
第二个问题是,多个workers之间如何不冲突地使用资源?因为多个workers可能在执行一个任务,这个任务里面涉及的到的资源是共享的,而这些资源可能不能同时交给多个workers去使用,否则可能会产生逻辑错误。还有就是如果多个tasks之间有关联性,那么它们的资源也可能有关联性,可能在使用方面也是有顺序性和独占性。
因为,并发编程所有的理论,实现,设计模型,就是要解决这两个问题:「协调并发执行循序」,「协调资源的使用」。
为了解决「协调并发执行循序」,「协调资源的使用」这两个问题,人类做了大量的研究,产生了很多的研究结果,制造了很多解决实际问题的工具。而我们要学习的就是这些东西了。
为了协调并发执行顺序和协调资源的使用,我们需要协调的手段。比如,如何让Worker A等待Worker B完成了特定任务后,再继续执行任务?
还比如,如果Worker A和Worker B都要使用Resource X,但是不能同时对Resource X做操作,怎样才能让它们不同时操作Resource X?
这种情况下,我们往往使用「锁」来实现「互斥」,「独占」,来完成「协调执行顺序」和只允许一个worker访问某个resource的工作。
于是,「锁」,也就是lock的实现,如何可靠地获得锁,如何可靠地释放锁,就是一个研究领域。
什么叫「可靠地获得锁」?我们可以自己想想。应该可以大概想到一些内容,比如:不能让两个worker同时获得同一个lock,那么这个lock也就没有意义了。所以在lock的实现方面,我们不能让这种事情发生。
为了避免这种事情发生,最终我在硬件上有保障,保证lock的可靠性,也就是说,硬件必须要提供atomicity,原子性。体现在观测结果上,所有worker都需要观测到一个object的「状态改变」的「一致性」。不能说A观测到一个状态的改变,B没观测到,如果是这样的话,锁的实现是无从谈起的。
大家是不是觉得概念上很抽象?但是在软件的实现上,我们经常会和上面所说的atomicity打交道的。
最常见的就是Java里面的volatile这个关键字。如果我们一个「变量」不使用volatile这个关键字,那么Java的「虚拟机」可能就不会「同步」这个「变量」。如果你的程序是multi-threaded,也就是「多线程」的,每一个thread里面观测到的这个「变量」的值可能是不一样的。
为什么?因为层次的丰富性。什么意思?我们的程序面对一个多层的世界:虚拟机,操作系统,CPU。
现代的虚拟机或是操作系统使用的是复杂的虚拟内存实现,为的是效率最大化。对于多线程,使用的是allocation on demanding的策略。也就是说,能共享的数据,就尽量共享,需要分割的数据,再独立划分空间。
然后是CPU,现代的CPU都提供缓存,提高运行速度,多核CPU下,每颗CPU有自己独立的缓存。你看到的数据是CPU缓存数据,而不是内存里面的实际数据。
于是什么时候CPU更新缓存就成了问题。单线程的程序没有这个焦虑,但是多线程的程序里面,就算是一个Thread更新了一个「共享变量」的数据,另一个Thread也不一定能看得到这个改变。
为什么?这里面有好多层要考虑的因素:首先,CPU的缓存也是提供给操作系统指令接口,由操作系统负责更新策略的。
其次,虚拟机在实现的时候,要提供给代码编写者接口控制CPU的缓存更新。比如Java的volatile关键字。一切为了性能。
但是对于新手,就不知道这些,可能觉得,我在一个thread里面更新了一个共享数据的值,那么在另一个thread里面就可以观测到,其实根本不是。
如果你不使用volatile关键字,另一个thread读到的可能还是另一个CPU里面的「缓存」数据,而不是「内存」里面更新后的数据。下图展示了CPU缓存,Thread观测到的数据,以及内存的关系1:
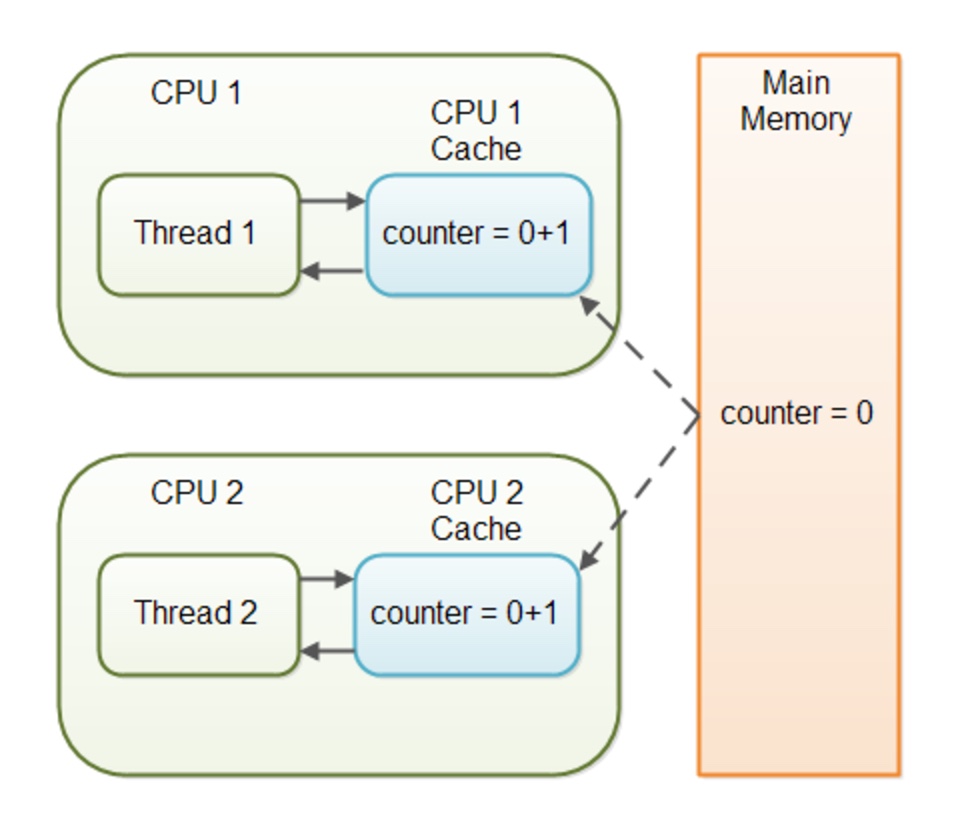
所以,lock的实现,要基于所有这些层次丰富的世界进行考量,要考虑到所有的观测不一致的可能性。所以说,软件的「锁」的实现,是基于「硬件」,「操作系统」,「虚拟机」一个综合考虑,最终落到一个实处:CPU是一个晶振芯片,时间的原子性。
我们之前说,volatile关键字保证CPU每一个核都会更新自己的cache,保证多个thread下,某一个thread更新了一个变量,这个内存里面的数据改变,可以更新到每一个CPU的cache里面去。
那么我们可以再想,如果CPU的某一个core的cache正在更新的时候,这个core上面的thread正在读取这个变量怎么办?岂不是成了薛定谔的猫?
所以在硬件设计上面,就不能允许这种情况的存在:CPU的指令是一条一条执行的,而cache的更新则保证会在前一条数据修改指令结束后,下一条读取指令到来前,cache更新完毕,而不管是哪个core写,哪个core读。
如果没有CPU的原子性作为保障,一切秩序都无从谈起。
而为什么我们使用volatile关键字,就可以保证一个变量会更新到CPU所有core的cache里面去了呢?
为什么并发编程难?层次的丰富性。
好,我们来看CPU的cache的实现2:
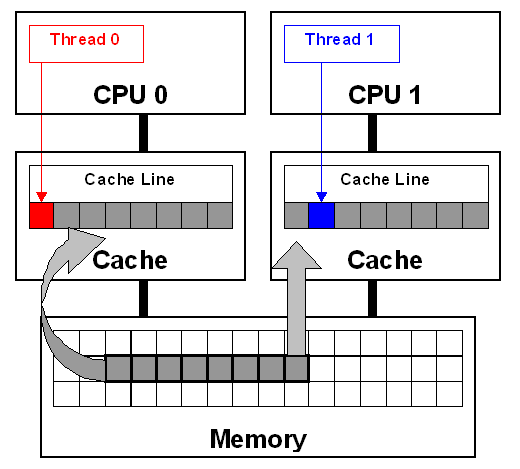
如上所示,CPU里面有Cache Line的概念,也就是说,如果是在一条cache line的的数据被修改,那么一条线上各个CPU的cache都要被更新。就像上面看到的那样,就算这条线上的某一个数据被更新,那这条线上所有的cached data都要从内存重新加载。Intel的这个设计,叫做MESI (Modified/Exclusive/Shared/Invalid) protocol。
而现代的编译器或是虚拟机,会去做一些优化工作,维护一个thread local变量,不让shared data放在一个cache line上面去,这样一个变量被一个thread更新的时候,并不会造成所有的cache line更新。为什么要这么做?当然是为了速度和效率。而volatile关键字当然就是保证这种编译器或是虚拟机内部不会做这种优化,保证这个变量一定会更新到cache line。
所以原子性的保证,来自于这么多层面,这是我们要了解的。
我们了解了Atomicity的概念,直到了这个是一切的保证。为什么这么说?比如我们让CPU执行两个指令:
x = 3
x = -4
那么x在某一个状态的时候,要么为3,要么为-4,不可以是-3,5这种毫不相干的状态。因此我们说如果一个operation是atomic的,硬件要保证这个operation的atomicity,否则计算的可靠性就无从谈起了。
从我们硬件使用者的角度来看,这是最起码的东西,但是从硬件实现者的角度来看,变量的赋值至少要经过:寄存器,CPU的二级缓存,DMA通道,内存单元。对于赋值还好,对于运算要考虑的更多。比如Intel在操作SSE寄存器的时候提供Memory Fencing的能力来保证原子性,目前不必理解细节,但是我们要知道硬件在设计的时候,提供Atomicity并不像使用者看到的那么简单。
Atomicity说的差不多了,关于锁的具体实现和具体分类我们后续再讲。接下来我们要想想协调workers的执行顺序的问题了。
首先得定义什么是执行顺序。
在现实生活中,我们对很多工作的顺序要求其实是不一致的:有的工作有严格的步骤,必须按照1,2,3这样的顺序完成。如果1没完成,不可以开始2,如果2没完成,不可以开始3。这种我们叫做blocking sequential work,首先,它是blocking的,1会把2给block住,2会把3给block住。
还有的工作,并不在意顺序,可以123,也可以231,怎样都行,只要123之间不会互相会影响就可以的。比如上面举的例子:
x = 3
x = -4
假如两个worker,一个让x=3,另一个让x=-4,如果我们允许结果是3或者-4,只要不是-3就行,这种也是非常简单的。
真正难的是更细微的同步协调层面。比如之前举例子用到的Java的volatile关键字这里。如果worker1把一个共享的变量x赋值3,此时worker2却看不到这个更新的变量,原因是worker1和worker2在CPU的不同core上面,而worker2的core cache和worker1的core cache没有同步,这种情况是允许的吗?
如果你的使用场景允许,就可以不使用volatile关键字标记变量,如果你的使用场景不允许这种不同的情况发生,就要使用volatile关键字,防止compiler进行的优化造成CPU的cache line不更新。
不允许的场景,我们叫做linearizable consistency。但是volatile关键字保证的是atomicity,一个变量的写入,保证所有的观测者都看到这个更新,但是不保证各个观测者之间的工作顺序,所以我们说linearizable consistency是nonblocking的。
我们再想另一个场景,在编译器里面,有时候,我们的目标代码会被优化,比如gcc编译器会提供好几个优化的级别。
高级别的优化,甚至会打乱源代码的执行顺序,编译器在认为破坏代码顺序不回影响运算结果的话,会做这种优化。为什么要打乱代码的执行顺序?因为CPU有pipeline的设计3:
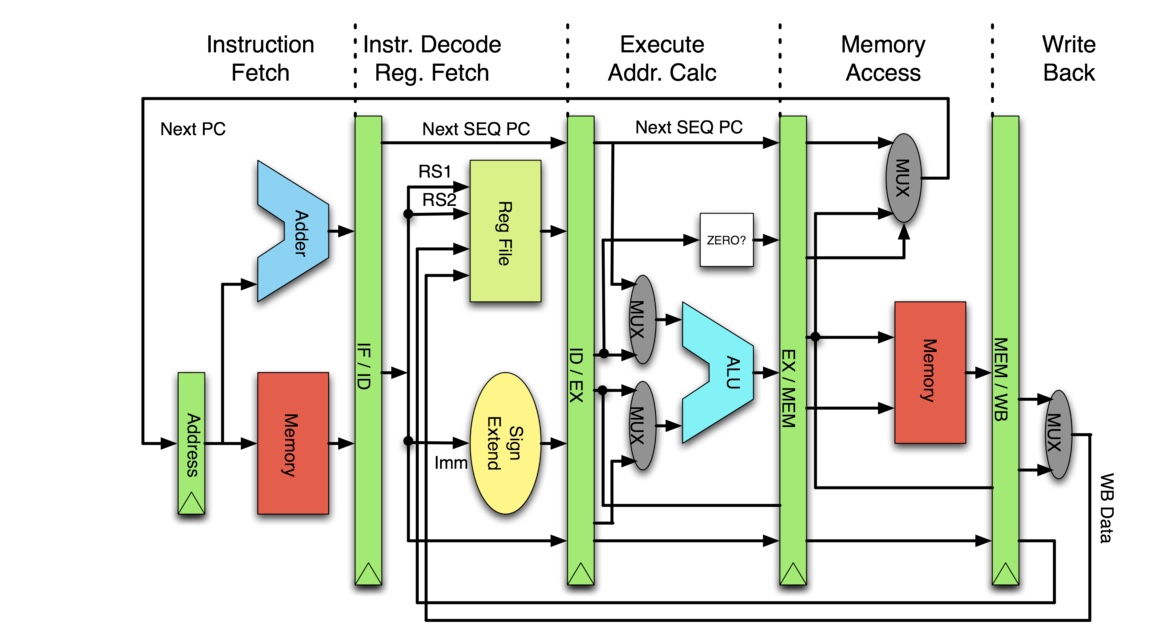
如上图所示,CPU内部有Instruction Fetch单元,Instruction Decode单元,Execution单元,Memory Access单元。因此,每一个CPU周期,不同的单元可以并行执行各自的任务。因此如果我们合理安排汇编代码,比如一条取内存的代码,跟着一条执行运算的指令,CPU就可以并行执行两条指令:
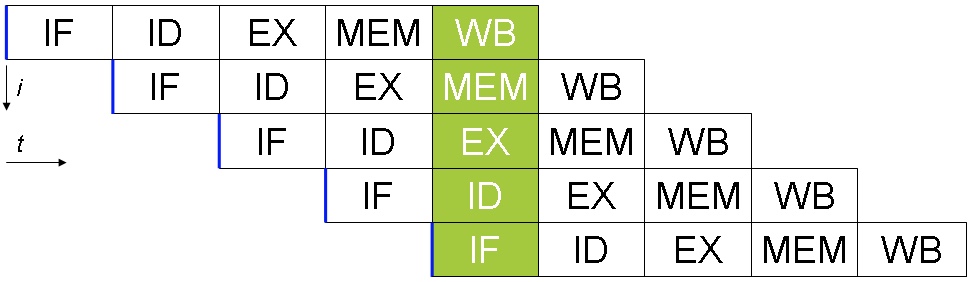
因此compiler可能会把源代码中的代码顺序重新安排得更合理,让CPU执行效率更高。
你的代码能够允许这种优化吗?如果不允许,那么你的代码很可能要求sequential consistency这个级别的同步,如果允许,那么你的代码可能要求quiescent consistency就可以。
到这里,给大家讲了atomicity,lock,consistency三个概念和它们背后的世界。来看一下关于并发这个领域里面很重要的概念transaction,也就是常说的「事务」。所谓「事务」,就是假设有工作x,y,z,要把它们看成一个整体,要么一起成功,要么一起失败。
如果成功,这个事务就算完成了,如果失败,那么所有的工作都要返回到初始状态,这个返回的动作,叫做rollback,中文就是「回滚」。
所以说事务是一个并发领域的综合应用,我们要考虑很多问题:首先,怎样把不同的任务可以做成一个整体?
然后,如果执行到工作y的时候失败了,那么怎样让工作回滚到xyz都没发生的初始状态?
还要考虑的是,当worker a在进行xyz这个事务的时候,我们要保证这个事务所用到的资源不受打扰,要如何整合资源并实现排他性?所有这些都是事务要考虑的范畴。
如果我们把网络加进来,问题会变得更为复杂,如果我们的工作x在机器a,工作y在机器b,工作z在机器c,之间是通过网络通讯完成的,那么我们怎么保证事务的可靠性?怎么保证在中间环节出错后,可以可靠的rollback?
所以「事务」这个领域的问题,不单纯是一个理论问题,而是一个和具体的世界打交道的问题。因此,所有有关「事务」的研究,不光是研究「事务成功」如何,或是「事务失败」如何rollback,而是要考虑,「事务失败」后还不能rollback,这些灾难的情况都有哪些可能,如何处理,这才是完成的拼图。
所以「事务」这个领域的话题太大了,模型也特别多,基于网络的事务协议更是复杂。个人觉得没必要学得面面俱到,但是会慢慢给大家分享一些这个领域最有价值的东西给大家。
- 上一篇 Linux驱动开发入门(四)
- 下一篇 日语学习笔记・03