使用Docker快速安装部署Spark
Docker中有关于Spark的image,我们可以拿来直接使用,把Spark玩起来。
推荐使用的是位于Github的big-data-europe团队做的这个Docker image项目:
https://github.com/big-data-europe/docker-spark
这个项目的优点是它包括了master和worker的images,我们可以到时候直接从docker hub上面pull下来,组成群集,不需要自己做复杂配置。
在这篇文章里,我们不讨论和群集有关的东西,先拿一个单独的spark服务,把它跑起来,因此使用spark-master这个image就可以了。这个image在docker-hub的位置如下:
https://hub.docker.com/r/bde2020/spark-master/
把这个image下载,并把容器跑起来,照着它给的文档里的命令执行就可以了:
$ docker run --name spark-master -h spark-master -e ENABLE_INIT_DAEMON=false -d bde2020/spark-master:2.3.0-hadoop2.7
在本地机器上执行上面的命令,就会下载相关的image:
下载所需时间较长,需要耐心等待。
Docker也支持配置网络代理,你可以根据自己的实际的网络情况进行配置:
下载完成后,docker就会根据image创建一个container,并运行起来这个container:
此时,我们可以用docker ps命令来查看在运行的这个容器:

可以看到,这个容器在运行了,它的名字是spark-master。我们用下面的命令登录进这个container:
$ docker exec -it spark-master bash
这样,我们就登录进了这个container(是一个ubuntu的container):

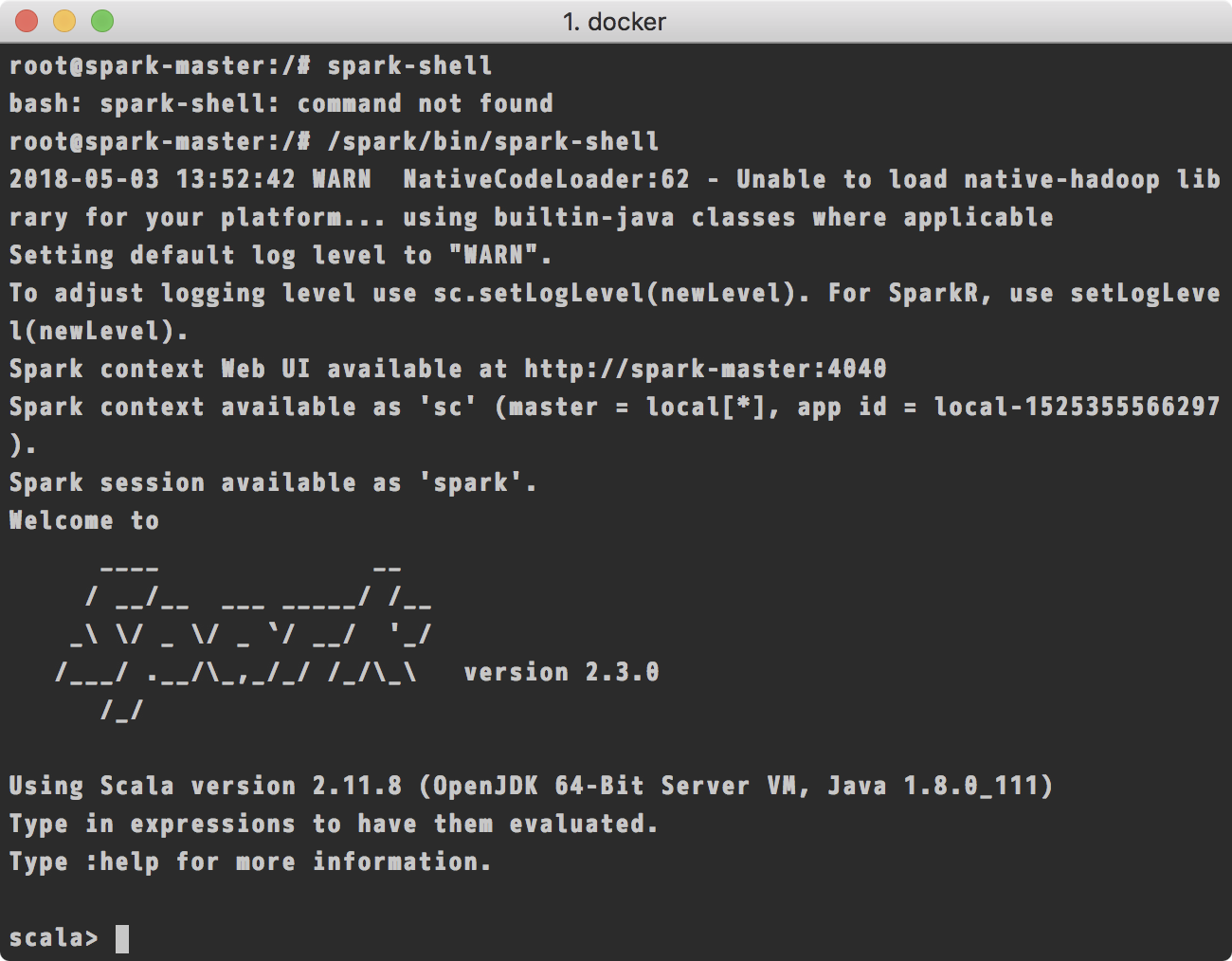
可以看到spark已经安装好了,并且此时spark服务已经跑起来了。我们可以使用spark-shell命令来访问spark服务:
spark的平台默认是使用Scala语言的,它现在也有python的接口,具体可以看spark的文档来学习:
https://spark.apache.org/docs/latest/quick-start.html
当我们用完这个容器以后,可以关闭掉它:
$ docker stop spark-master
此时这个容器停止服务了:
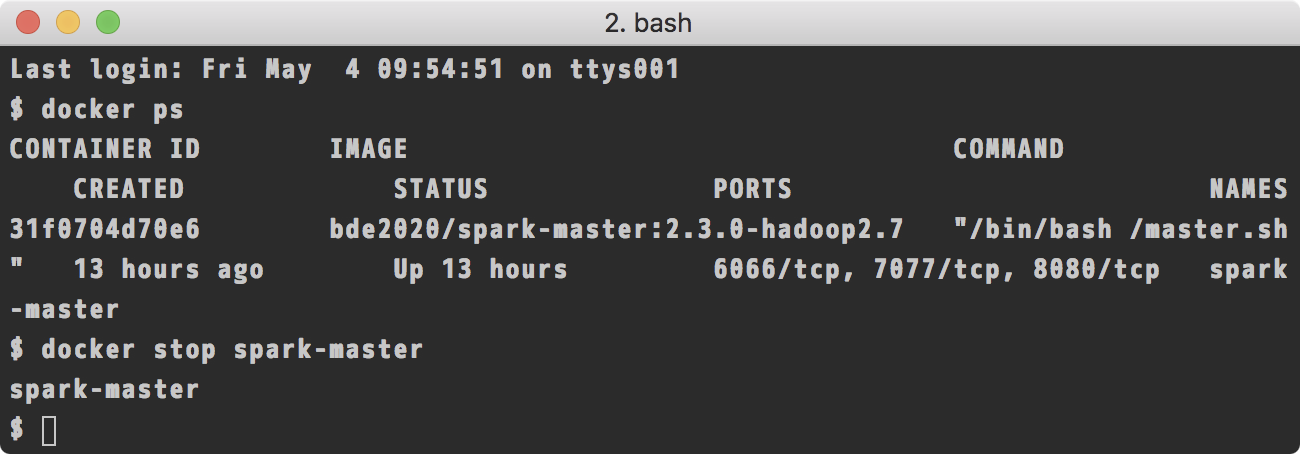
下次再想使用这个容器的时候,使用docker start命令即可:
$ docker start -i spark-master
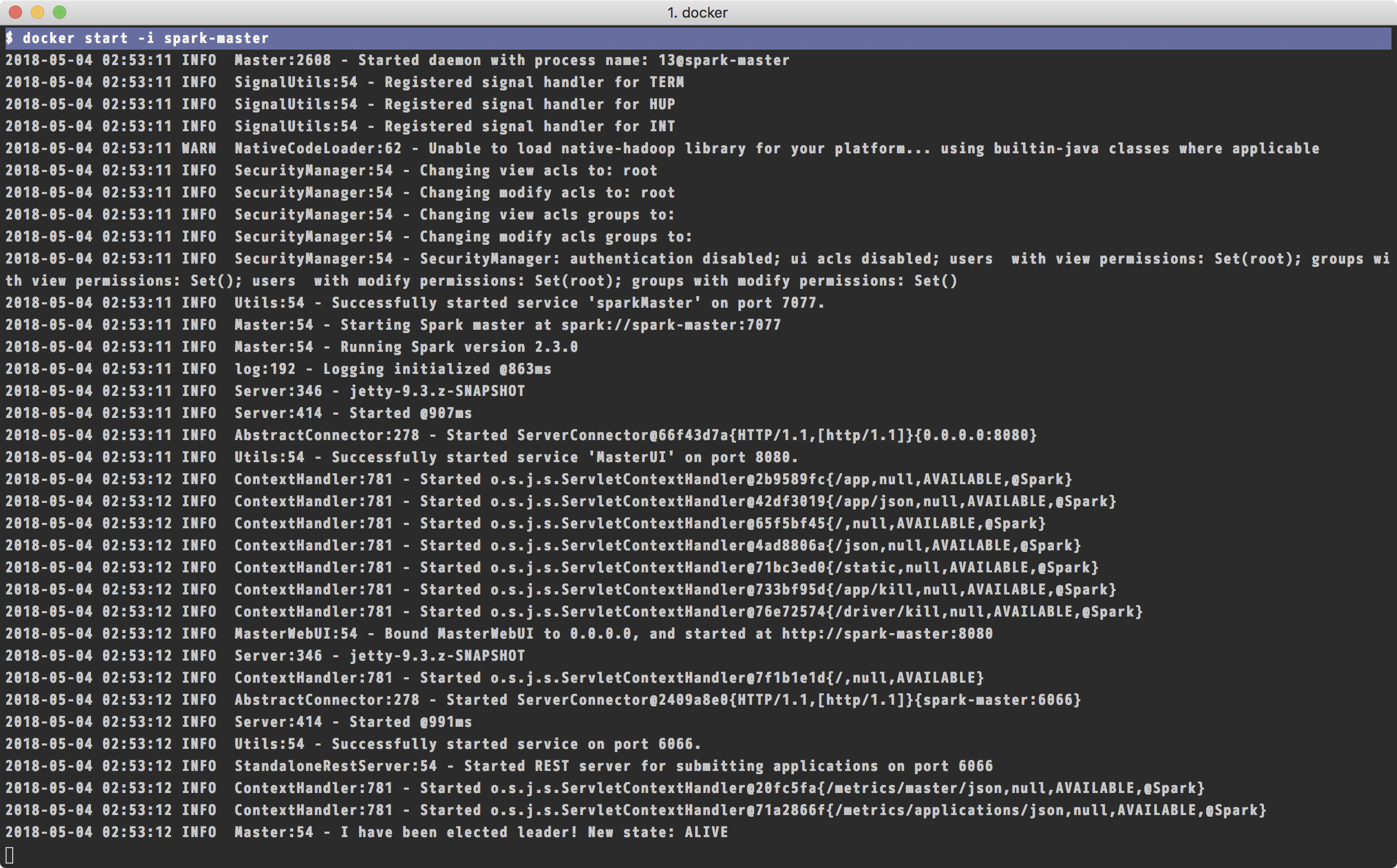
此时我们再开一个终端窗口,使用上面介绍的docker exec命令登录进容器就可以了。
本文就介绍到这里,后续我还会再写一系列文章,介绍更多Spark和Hadoop相关的内容。