在MacOS上安装Hadoop的流程记录(下)
本文简单记录在MacOS安装,配置,启动Hadoop的过程。本文是下篇,主要介绍Yarn的配置和启动,以及执行MapReduce任务的方法。
在上篇的基础上,我们继续配置yarn-site.xml:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
上面的配置指定了resource manager为localhost。
配置完成后,我们先使用start-dfs.sh来启动hdfs:

仔细观察这个启动过程,可以看到实际上有三部分组件被启动了,分别是namenodes,datanodes,secondary namenodes。其中namenodes主要是用来管理hdfs里面的数据metadata,而datanodes用于实际的数据存储。关于secondary namenodes的用途,可以查看这篇文档:
以下是hdfs的一个架构图:
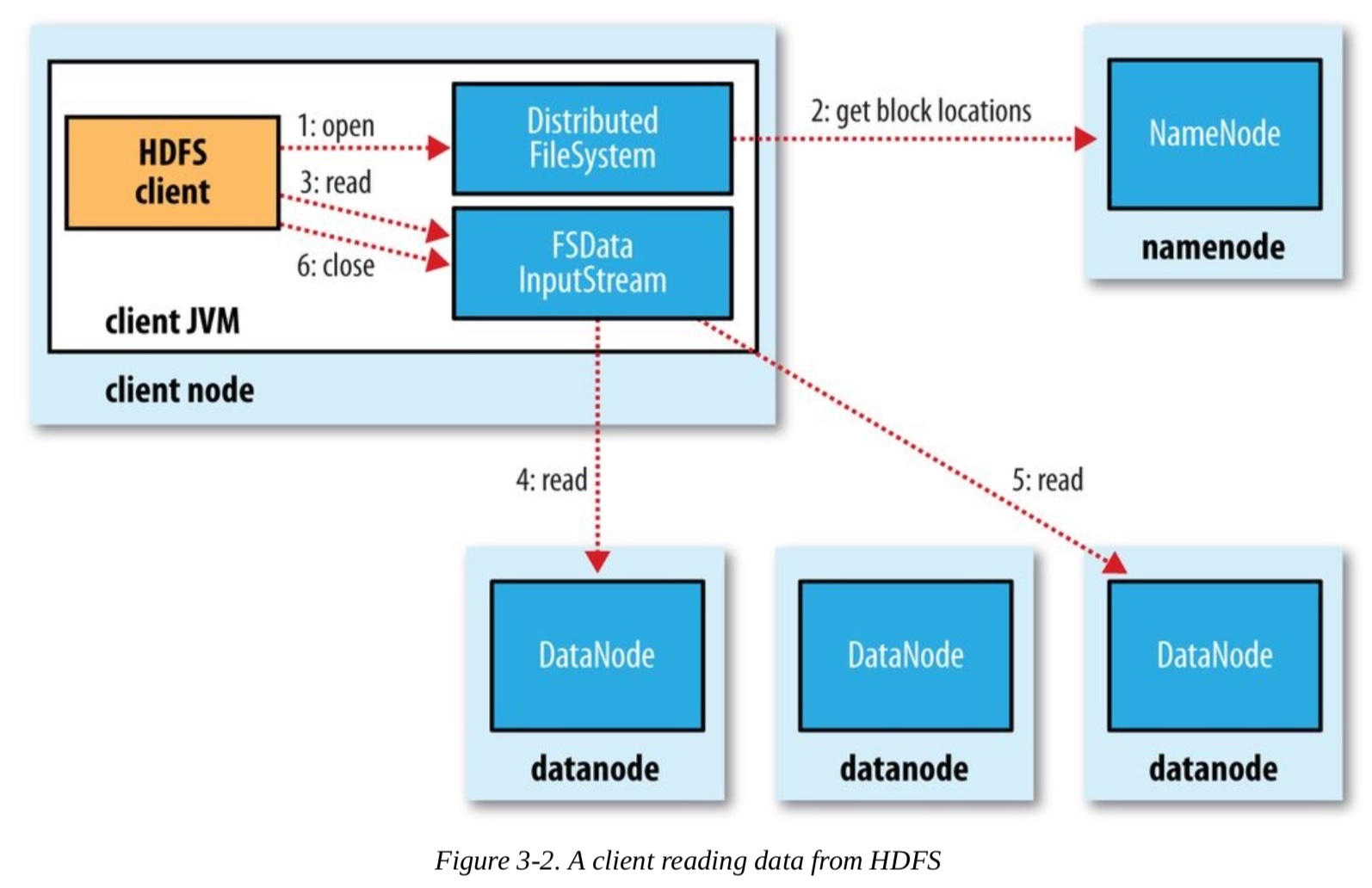 (图片来源:Hadoop: The Definitive Guide, 4th Edition)
(图片来源:Hadoop: The Definitive Guide, 4th Edition)
整个架构是分布式的,各个模块可以分散部署,也可以像我们这个文档里面说明的这样,集中部署在一台机器上面。
hdfs启动以后,我们使用start-yarn.sh来启动Yarn服务:
可以看到Yarn包含两个组件,分别是resourcemanager和nodemanagers。
以下是Yarn的架构图:
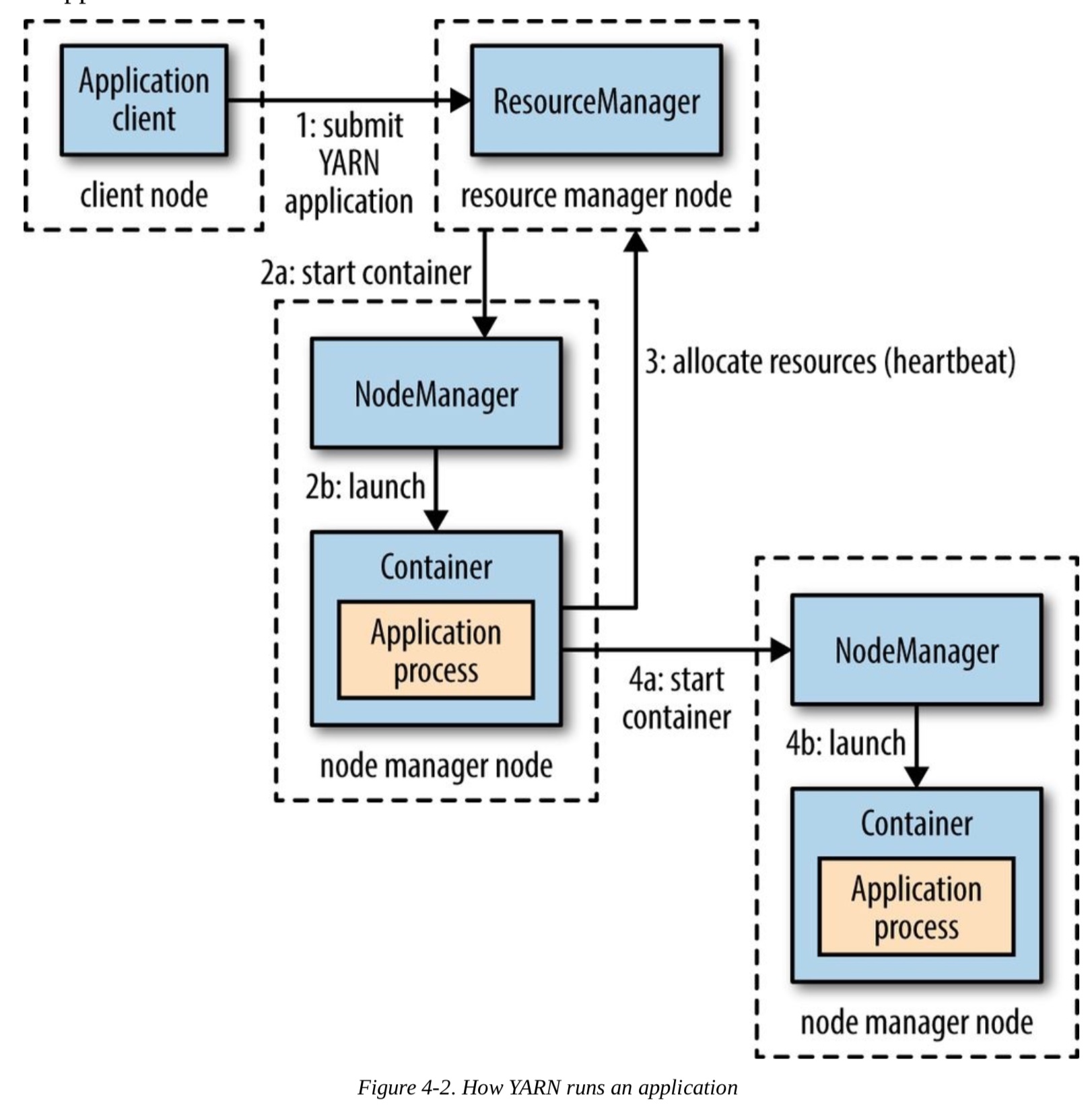 (图片来源:Hadoop: The Definitive Guide, 4th Edition)
(图片来源:Hadoop: The Definitive Guide, 4th Edition)
可以看到Yarn是如何通过ResourceManager来提交map reduce任务的。
以上的启动过程完成后,我们可以查看hadoop的实际文件结构。Hadoop默认是在/tmp目录下保存文件,目录名称是用户名 + hadoop的格式。下面是我机器上的数据:
可以看到出了一些pid进程文件以外,还有hadoop-weli这个数据目录。以下是目录中的内容:
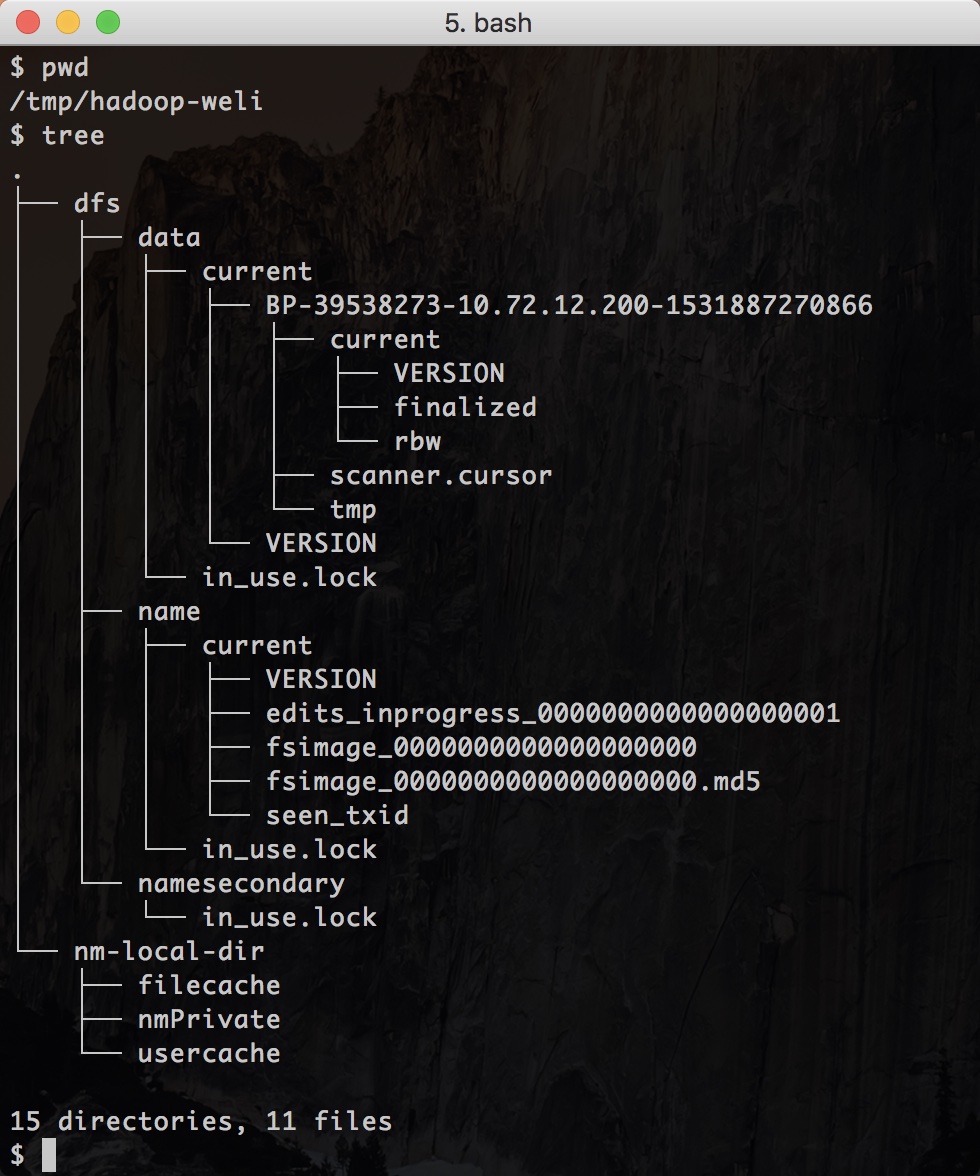
从上面的图可以看到各个模块生成的初始数据。
接下来我们可以试着提交一个map reduce的任务:
$ pwd
/usr/local/Cellar/hadoop/3.1.0/libexec/share/hadoop/mapreduce
$ yarn jar ./hadoop-mapreduce-examples-3.1.0.jar pi 16 1000
上面的这个hadoop-mapreduce-examples-3.1.0.jar是hadoop自带的例子,我们把它通过yarn命令进行提交,用它来跑一个运算Pi的数值的map reduce任务。
以下是任务的运行情况:
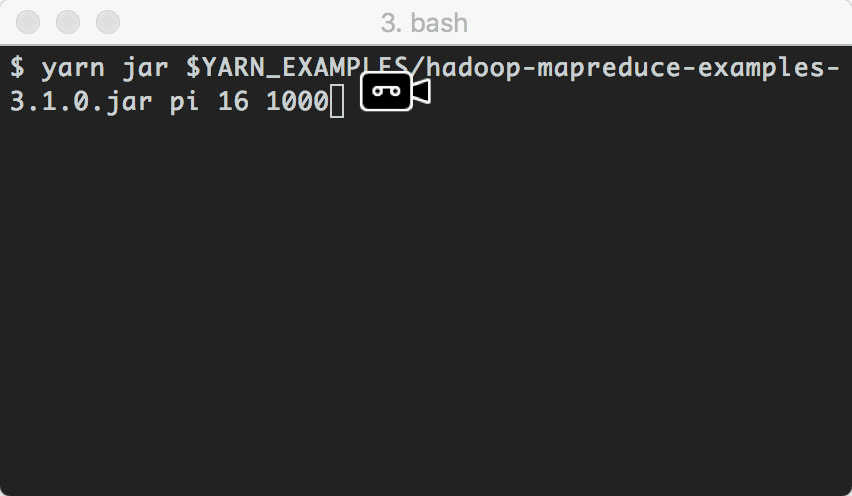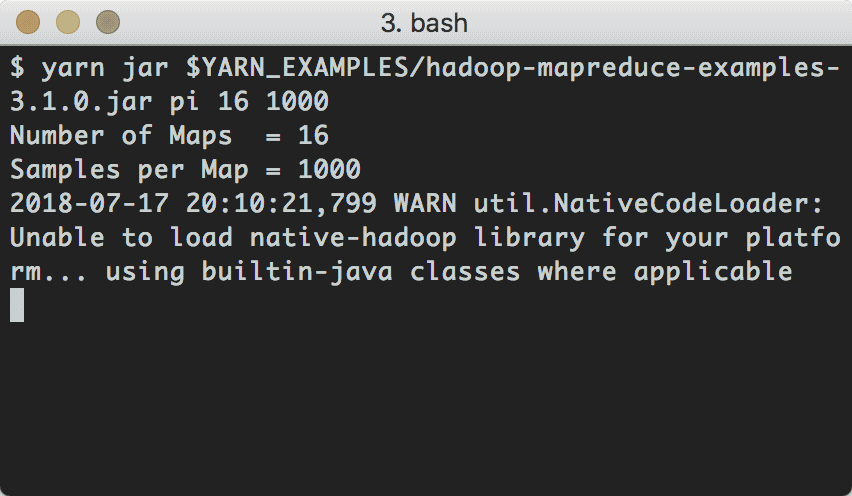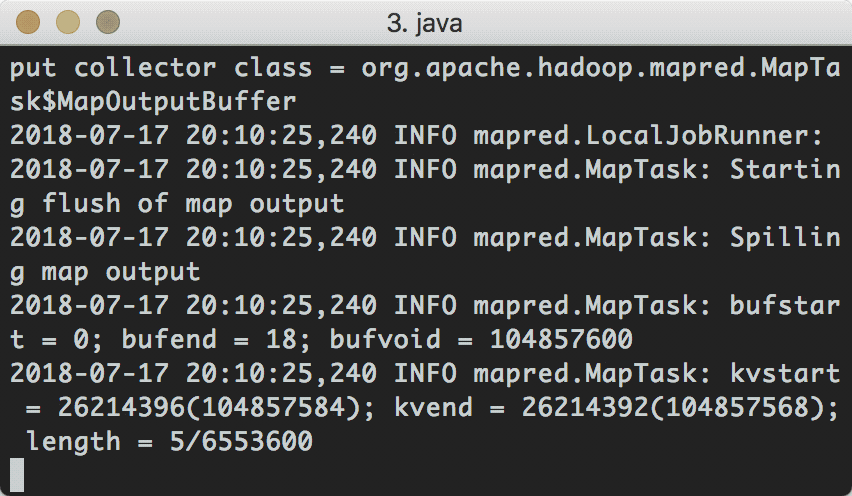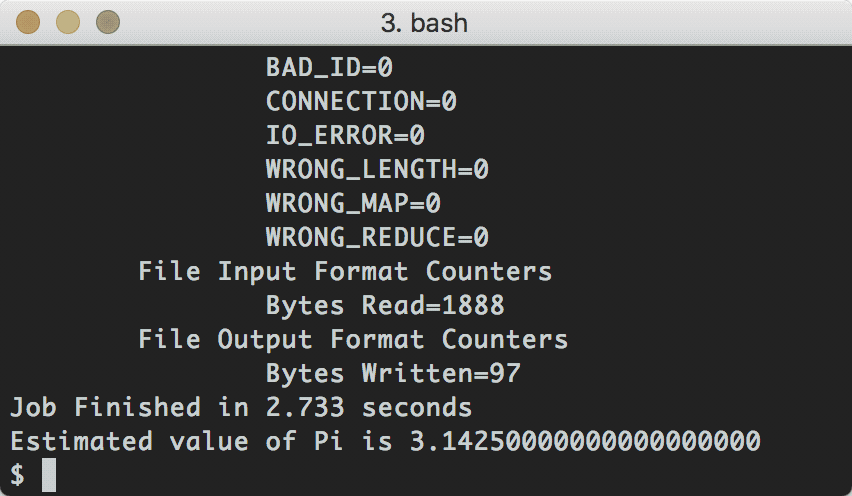
上面的任务执行结果如下:
Job Finished in 2.733 seconds
Estimated value of Pi is 3.14250000000000000000
如果你对上面这个例子的源代码感兴趣,可以在这里查看源码:
在上面的任务执行完成后,我们可以重新查看/tmp中hadoop的文件数据的变化:
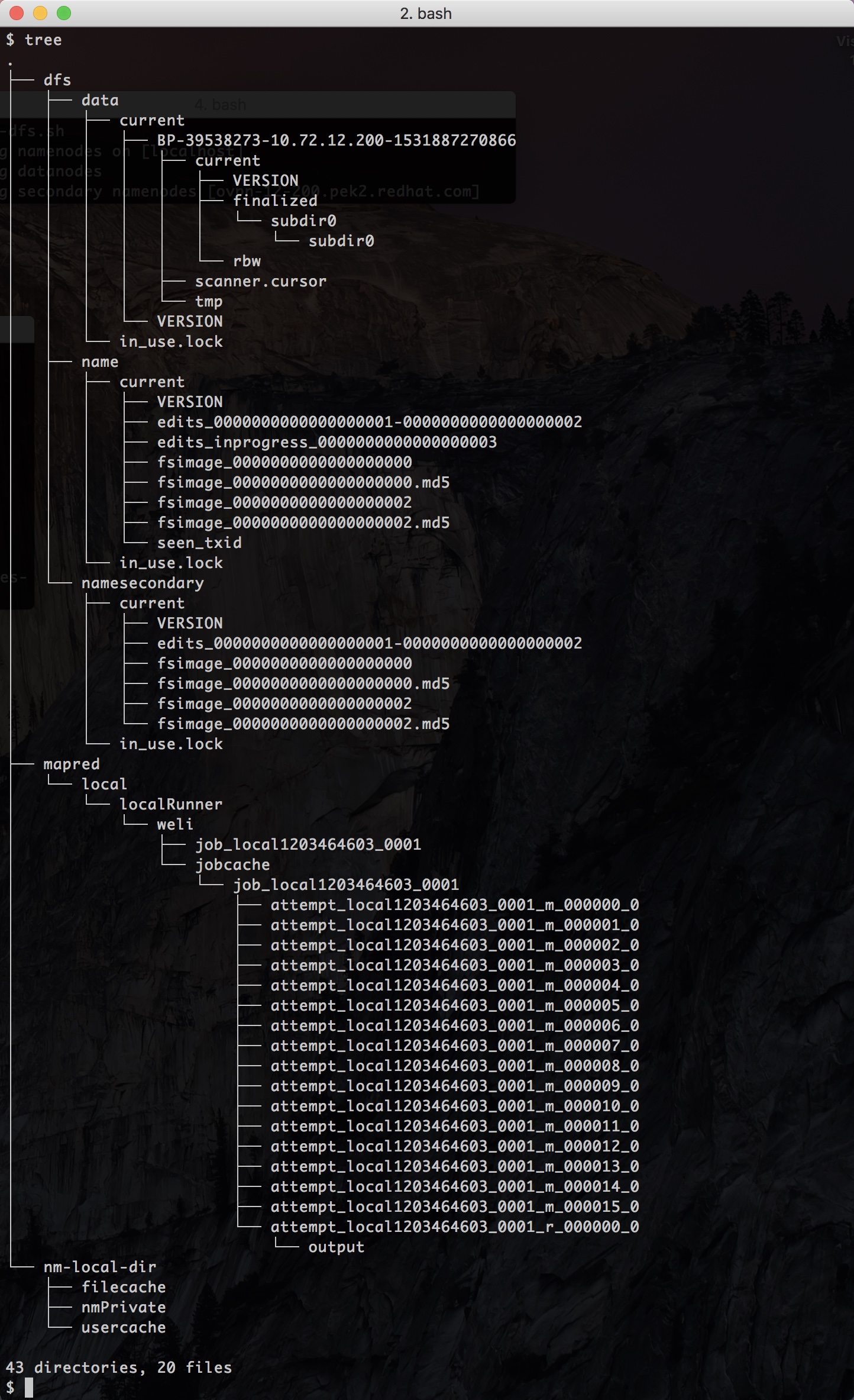
可以看到多了一个mapred目录,里面有我们这次任务(job)的执行日志。
以上就是Yarn的配置,以及mapreduce任务的执行过程。本文虽然是下篇,但是这两篇文章加起来,只是对hadoop的一个初步体会。后续我还会继续写文章介绍如何撰写一个mapreduce任务,以及围绕着hadoop的各种工具的使用。