MacOS下面设置Solr的中文分词
本文记录MacOS下Solr的中文分词器的配置过程。
使用brew命令安装好Solr:
$ brew install solr
安装好以后,可以找到solr自带的一个smartcn的分词包:
$ pwd
/usr/local
$ find . | grep smartcn
./Cellar/solr/7.4.0/libexec/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-7.4.0.jar
这个是给中文做分词用的,我们把它拷贝到solr的项目目录中:
$ pwd
$ /usr/local/Cellar/solr
$ cp ./7.4.0/libexec/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-7.4.0.jar ./7.4.0/server/solr-webapp/webapp/WEB-INF/lib/lucene-analyzers-smartcn-7.4.0.jar
拷贝完分词包以后,我们启动solr:
然后创建一个新的core:
$ solr create -c foo
WARNING: Using _default configset with data driven schema functionality. NOT RECOMMENDED for production use.
To turn off: bin/solr config -c foo -p 8983 -action set-user-property -property update.autoCreateFields -value false
INFO - 2018-07-22 21:26:23.679; org.apache.solr.util.configuration.SSLCredentialProviderFactory; Processing SSL Credential Provider chain: env;sysprop
Created new core 'foo'
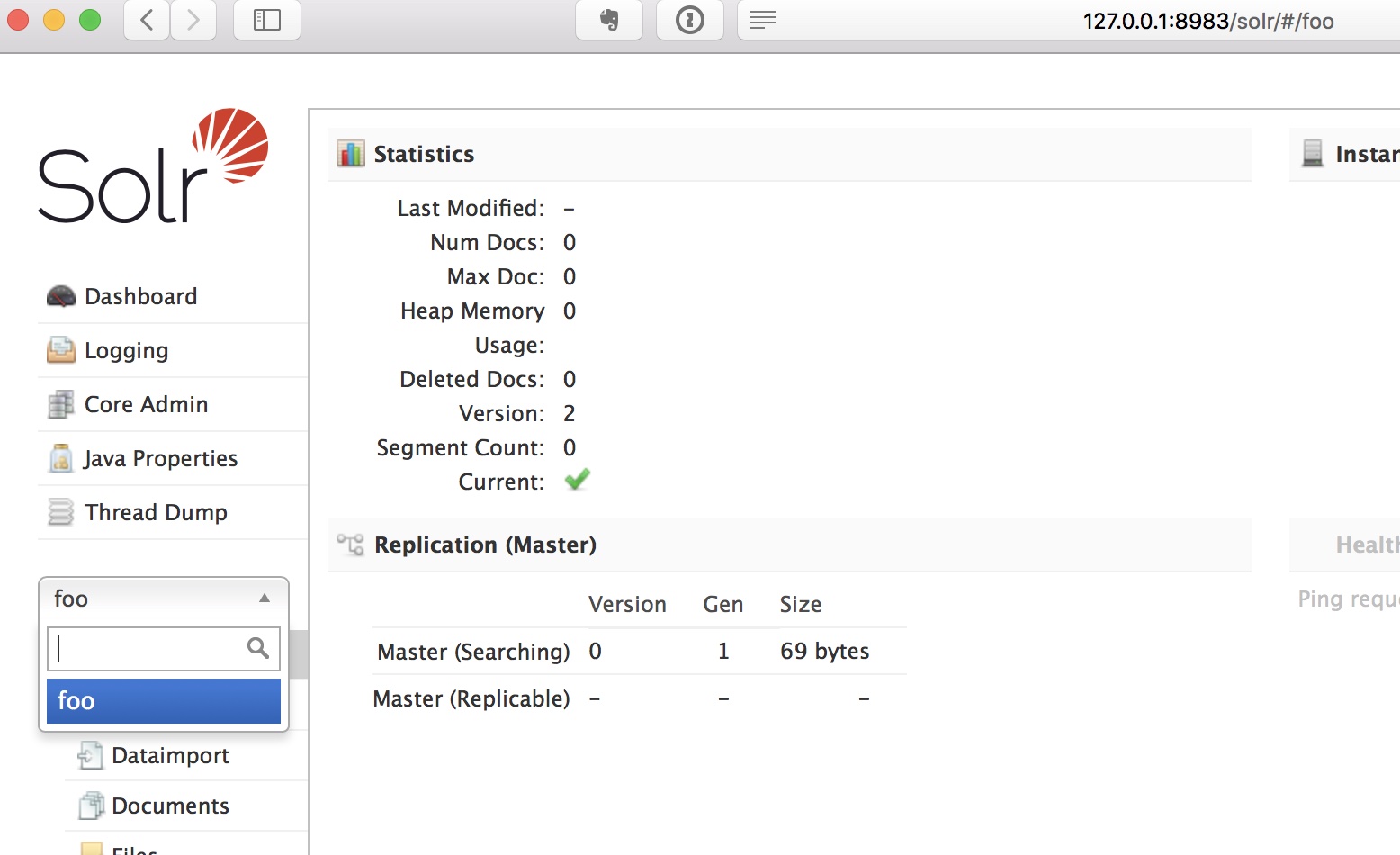
启动solr并创建了foo这个core以后,我们可以打开core对应的页面:
下面是管理端的页面状态:
此时我们要停掉solr服务:
$ solr stop
Sending stop command to Solr running on port 8983 ... waiting up to 180 seconds to allow Jetty process 15826 to stop gracefully.
此时我们要查看foo这个core的相关配置文件:
$ ls /usr/local//Cellar/solr/7.4.0/server/solr/foo/conf/
lang managed-schema params.json protwords.txt solrconfig.xml stopwords.txt synonyms.txt
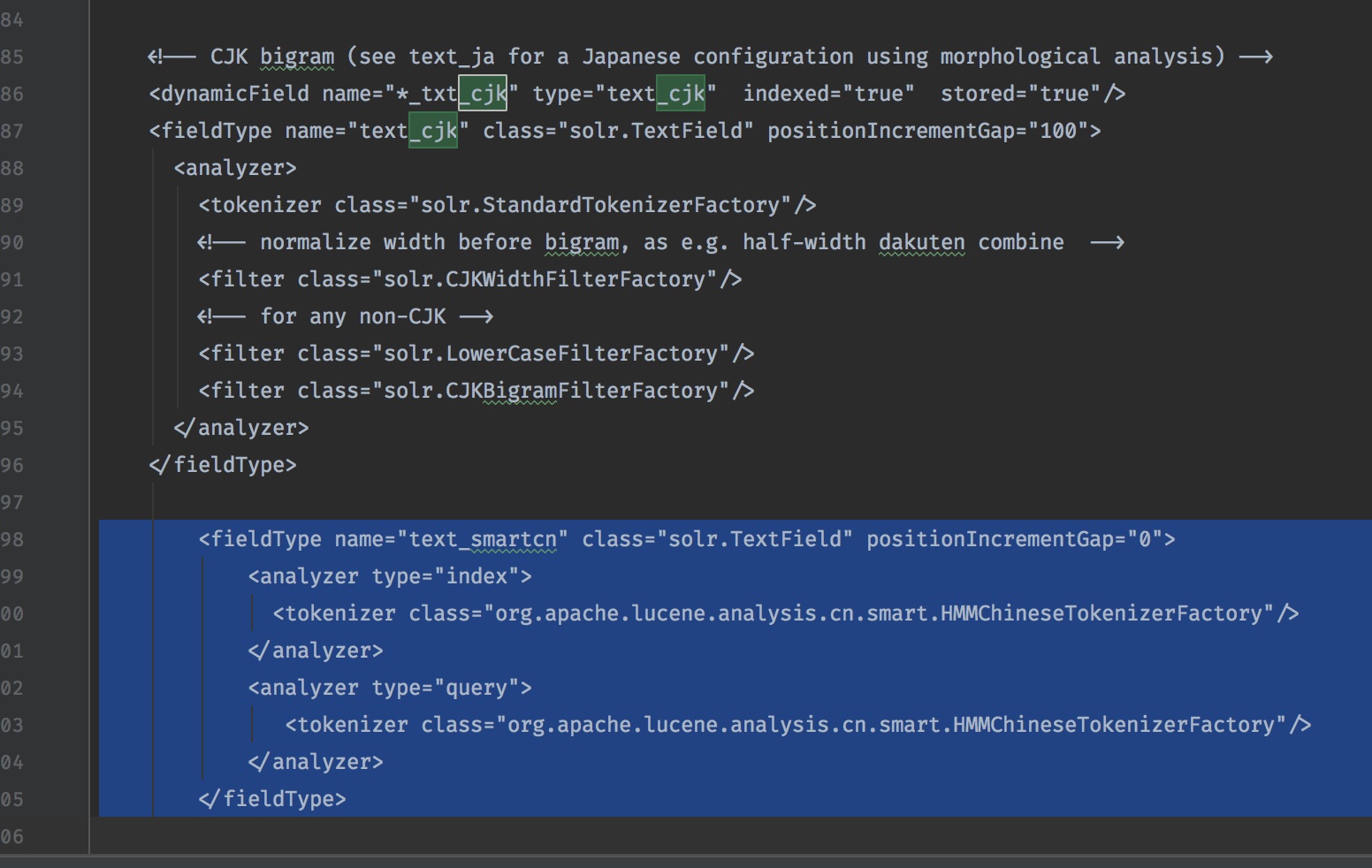
可以看到一个名为managed-schema的配置文件,这个文件里面配置了各种analyzers,我们要把上面那个smartcn的分词包配置进这个文件:
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
上面这段添加到这个CJK的fieldtype配置下面就可以了:
这样我们就配置好了中文分词器。接下来就是重新启动solr:
$ solr start
服务启动完成后,我们回到solr的管理页面,选择foo这个core,然后进入analysis页面:
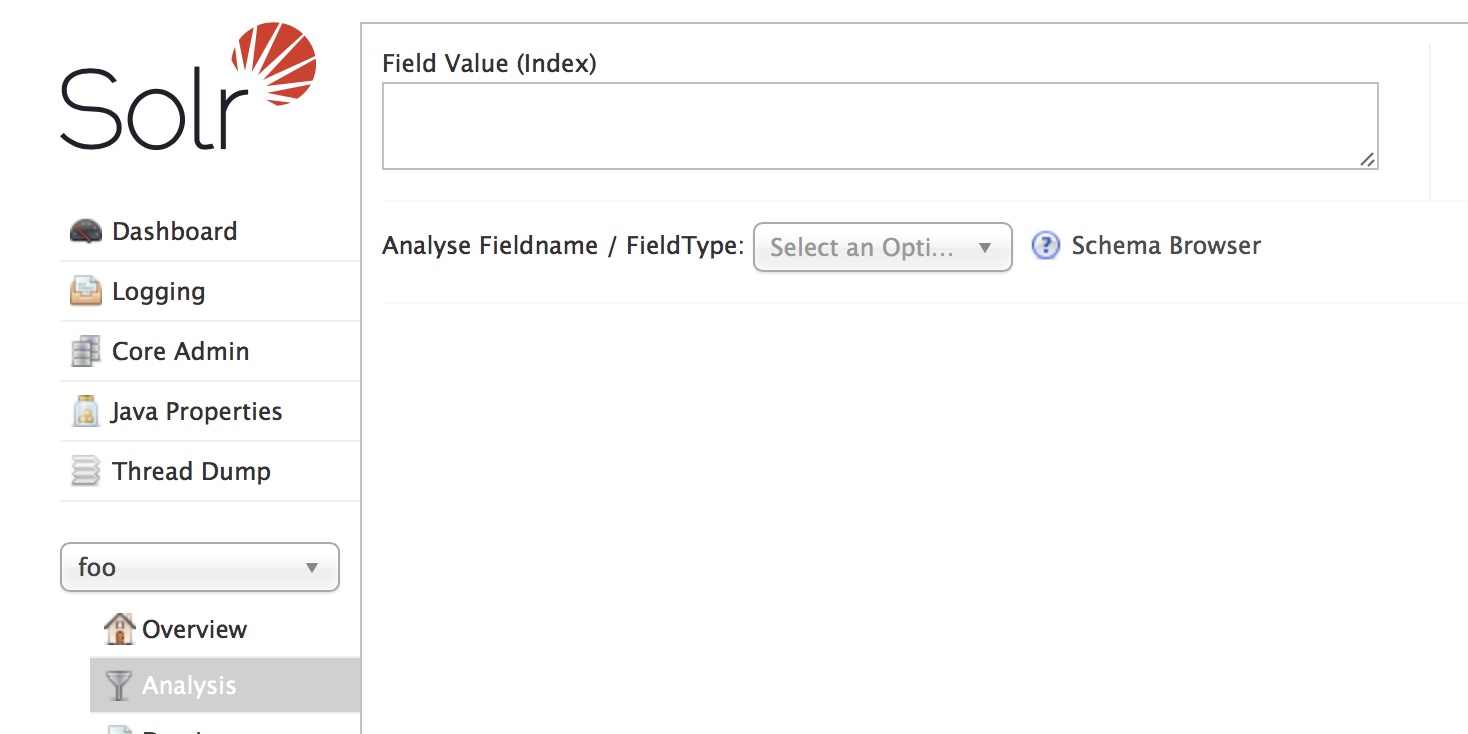
然后我们输入一段中文,再使用配置好的text_smartcn分析器:
设置完成后,点击”Analyse Values”,我们就可以看到分词的结果了:
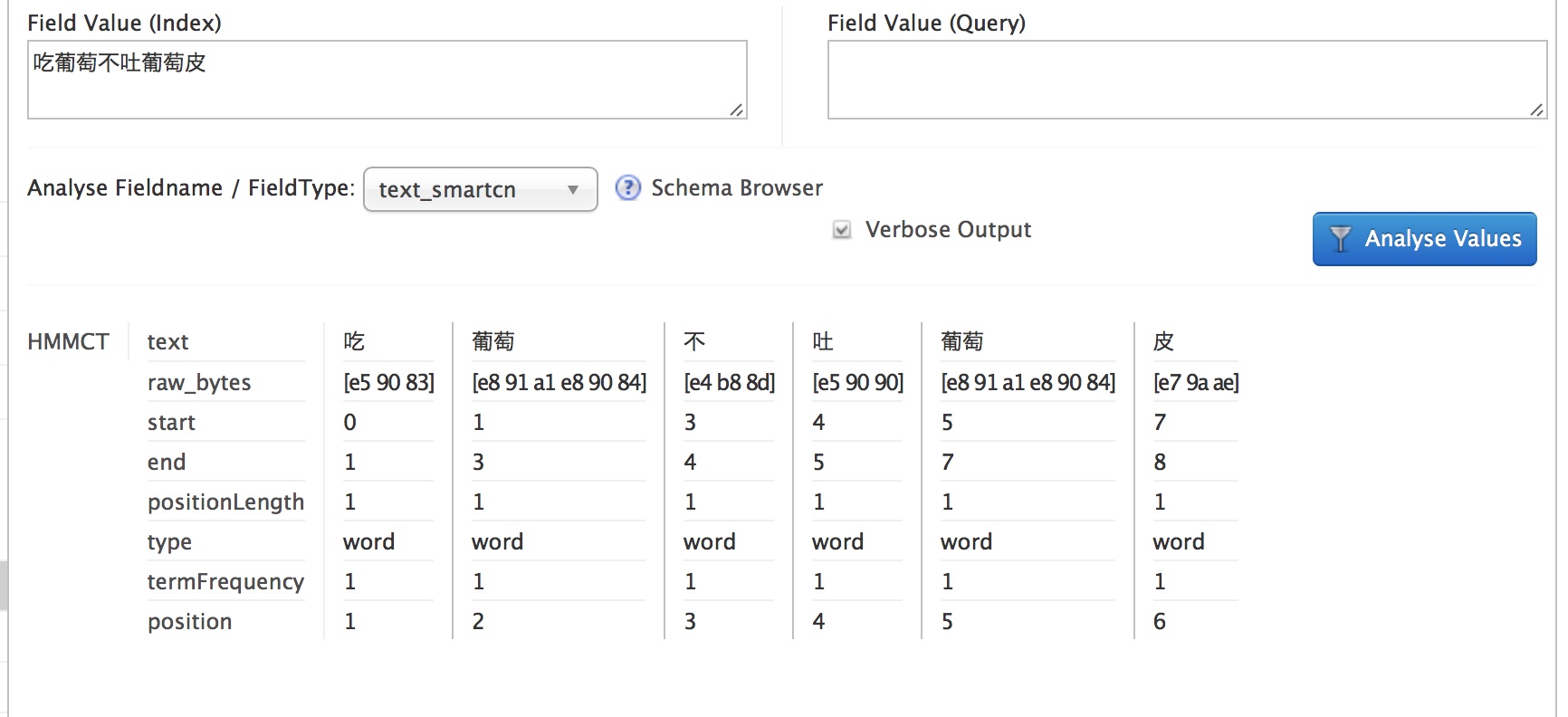
这样,Solr就可以对中文进行分词了,从而支持对中文词汇的检索。