Avoiding Blocking Issues When Using Quarkus Reactive
Writing asynchronous code is a very different experience because the code will not run sequentially, so you have to think about the racing conditions and other complex order problems.
In Quarkus, it provides a fully reactive environment, which means, it provides reactive components such as quarkus-resteasy-reactive and quarkus-reactive-pg-client to make your project fully asynchronous. In addition, the component like quarkus-hibernate-reactive-panache makes the problem more complex, Because it related with asynchronous transaction propagation, and it is a very error-prone field even if you write code carefully. In this article, I’d like to share some of my using experiences of the Quarkus Reactive framework, and also the problems I’ve met during the coding process.
Quarkus uses Mutiny as its underlying reactive framework, and uses Vert.x as its service engine. Both of these two frameworks have some confinements to the reactive code you are writing. For example, if you are using quarkus-resteasy-reactive, then you cannot write your non-blocking service like this:
@GET
@Path("/foo")
public Uni<Response> foo() {
var two = Uni.createFrom().item(1)
.onItem().transform(one -> one + 1)
.await().atMost(Duration.ofSeconds(3));
return Uni.createFrom().item(Response
.status(Response.Status.OK)
.entity(two)
.build());
}
The above code creates a Uni instance which is async, but the method called its await method, so if we start the Quarkus server and called the above service, we will get the following error from Quarkus service side:
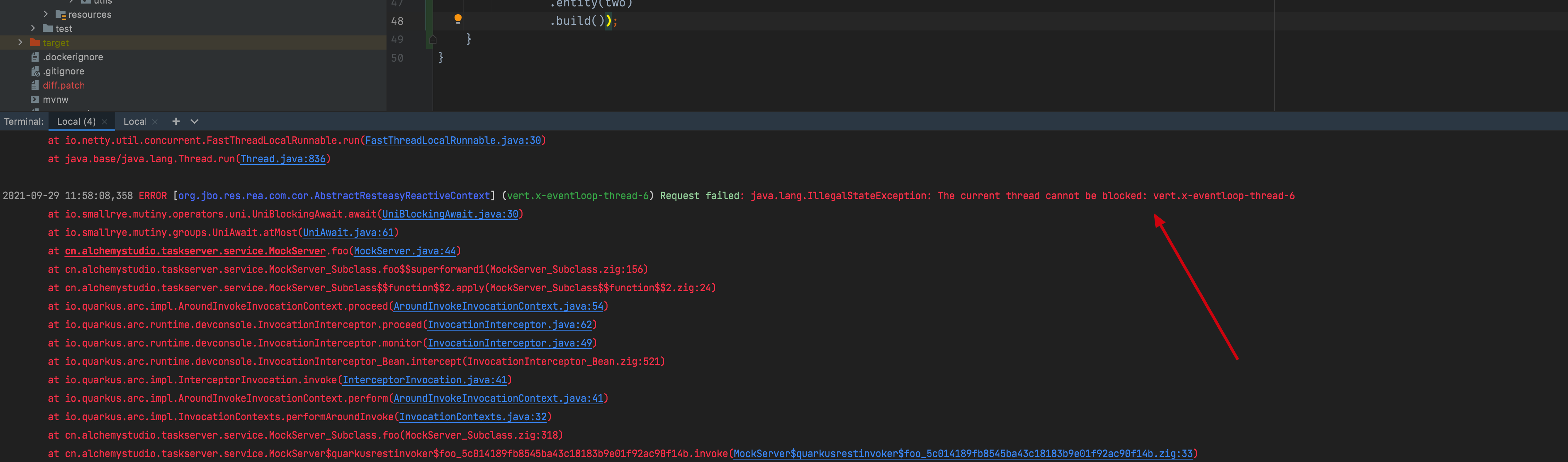
From the above output, we can see Quarkus complains above the thread is blocked, and we can see this error is thrown from the underlying Vert.x layer. This is because in our service code, we have called the await() method of Uni, which is provided by Mutiny framework, and it is blocking the Vert.x request thread. So if we do want to block the thread like this, then we need to annotate the method with the @Blocking annotation like this:
@GET
@Path("/foo")
@Blocking
public Uni<Response> foo() {
var two = Uni.createFrom().item(1)
.onItem().transform(one -> one + 1)
.await().atMost(Duration.ofSeconds(3));
return Uni.createFrom().item(Response
.status(Response.Status.OK)
.entity(two)
.build());
}
The @Blocking annotation is provided by the SmallRye project and Quarkus implements it:
io.smallrye.common.annotation.Blocking
After annotated the above service with this annotation, then the service can be correctly called:
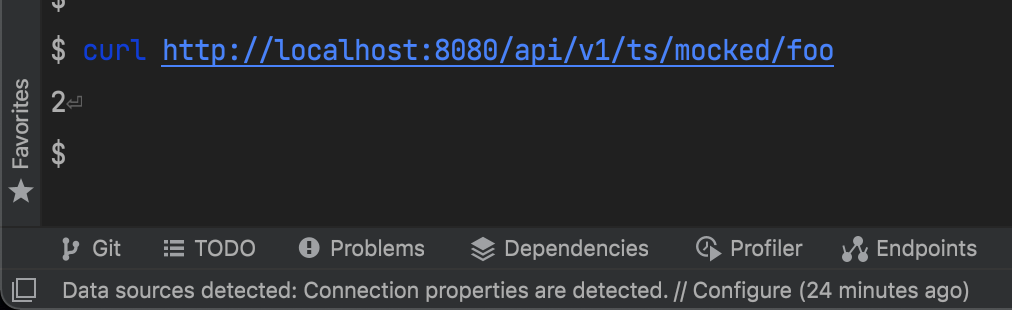
From above screenshot we can see our service can serve the request correctly now, and gives back the expected result.
In addition, since 2.2.1.Final version of Quarkus, the resteasy-reactive can judge your service method is blocking or non-blocking based on the return type of the service method, and here are the relative links about it:
- Quarkus - Quarkus 2.2.1.Final released - Hardening release
- Quarkus - RESTEasy Reactive - To block or not to block
Generally speaking, if your service method return type is wrapped by Uni, then Quarkus will treat your method as non-blocking, and if your service method is not wrapped by Uni, then your method is blocking. If you break this rule, then you have to annotate your service method with @Blocking or @NonBlocking respectively.
Besides resteasy-reactive, the next part worth writing is about hibernate-panache-reactive. The Hibernate Panache project is provided from Quarkus and Hibernate community, which is a new way to use Hibernate, and here is the relative article describing about it:
Generally speaking it provides the ActiveRecord pattern for the developer to deal with databases, and it can reduce a great amount of code needs to be written. Here are three core interfaces/classes of the Hibernate Panache:

From the above class diagram, we can see that Hibernate Panache has wrapped a lot of common database actions for us, including transaction management, and we just need to extend our entity class with PanacheEntity(or PanacheEntityBase if we want to manage id by ourselves). Here is how I used the Hibernate Panache in my own project:
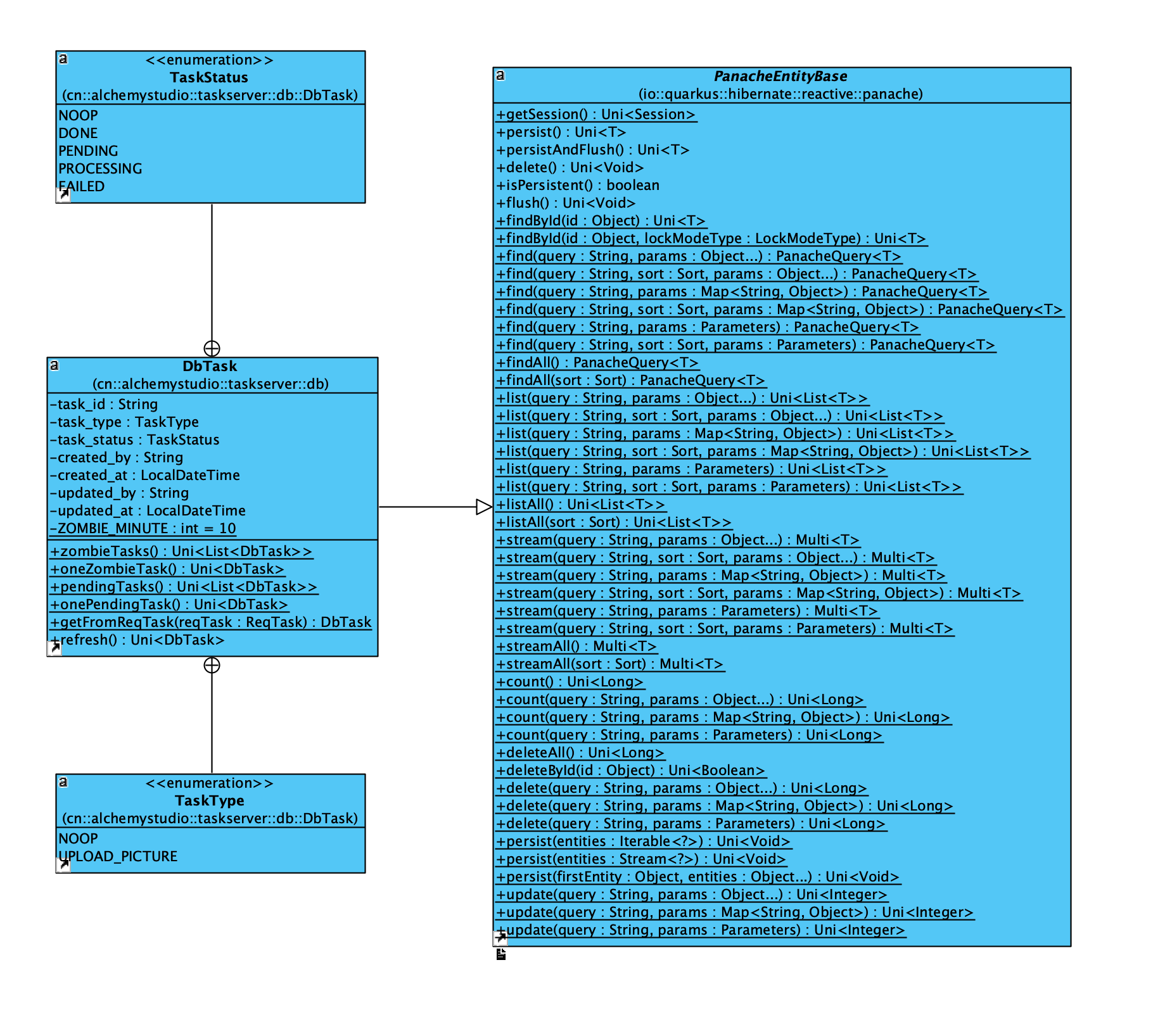
From the above class diagram you can see that I have a DbTask entity class which extends the PanacheEntityBase. But if you look carefully this PanacheEntityBase is the reactive one:
io.quarkus.hibernate.reactive.panache.PanacheEntityBase
This is provided by the hibernate-panache-reactive project, which brings Mutiny engine into hibernate-panache so it can allow developers to write database actions in a non-blocking way.
Writing non-blocking database is even harder, because it brings in some difficulties you won’t met when writing sequentially executed code, and here are some details in my opinion:
- Your database operations won’t be executed sequentially anymore.
- The transaction management becomes harder if you have paralleled database operations bound with one service request context.
For the first point of difficulty, here is a code example:
public void someDbOp() {
var op1 = list("task_status", Sort.descending("created_at"), TaskStatus.PENDING);
var op2 = find("task_status", Sort.descending("created_at"), TaskStatus.PENDING).firstResult();
var op3 = this.persistAndFlush();
}
As the code shown above, the above three operations are non-blocking, which means they won’t execute sequentially. Actually the above operations won’t be executed because we didn’t wait for the operations to be done. So to make above code run sequentially, we need to wait each operations to get done. Here is the code to do to the await:
public void someDbOp() {
var op1 =
list("task_status", Sort.descending("created_at"), TaskStatus.PENDING)
.await().atMost(Duration.ofSeconds(3));
var op2 = find("task_status", Sort.descending("created_at"), TaskStatus.PENDING).firstResult()
.await().atMost(Duration.ofSeconds(3));
var op3 = this.persistAndFlush()
.await().atMost(Duration.ofSeconds(3));
}
In above code, it wait each operation to be done and set a timeout duration. If the operation exceeds the duration, then it will throw runtime exception and the rest of the operations won’t be done.
The problem of the above code is that the whole methods becomes blocking. We can use something like Uni.combine() to make three operations run in parallel:
Uni.combine().all().unis(op1, op2, op3).asTuple().onItem().invoke(results -> {
// deal with results
}).await().indefinitely();
As the code shown above, it uses Uni.combine() method to run the three operations in parallel, and after all the three operations are done, it encapsulates results in a struct called Tuple, and we can get the result from it for each operation.
The above code won’t control the execution sequence of the operations. If we do want to control the execution sequence of the code, then we need to use the subscribe() method like this:
op1.subscribe().with(result1 -> op2.subscribe().with(
result2 -> op3.subscribe().with(
result3 -> {
// deal with all results
},
err -> { // deal with op3 error
}),
err -> { // deal with op2 error
}), err -> { // deal with op1 error
});
The above code ensures the operation execution order. The disadvantage is that you can get return value from the with() clause, so if you want to get the result out of the clause, you need to maintain a variable outside the scope. In addition, the above code is fully non-blocking, which means if you need to ensure the operations are done, you need to use some kind of flag to wait for the operations done. Here is some code example:
static final AtomicBoolean flag = new AtomicBoolean(false);
public void someDbOp() {
var op1 =
list("task_status", Sort.descending("created_at"), TaskStatus.PENDING);
var op2 = find("task_status", Sort.descending("created_at"), TaskStatus.PENDING).firstResult();
var op3 = this.persistAndFlush();
var result = new AtomicReference<>();
op1.subscribe().with(result1 -> op2.subscribe().with(
result2 -> op3.subscribe().with(
result3 -> {
// deal with all results
result.set("blabla");
flag.set(true);
},
err -> { // deal with op3 error
}),
err -> { // deal with op2 error
}), err -> { // deal with op1 error
});
while(!flag.get()) {
// wait for a while
}
// flag set to true, results here:
System.out.println(result);
}
The above code uses a flag to control the execution order, so we can make sure we get the result finally. Though the code is fully non-blocking now, the complexity of the code greatly increases.
This is not the whole story yet: until now we haven’t considered the transaction. As this release noted, the Hibernate Reactive is not thread safe:
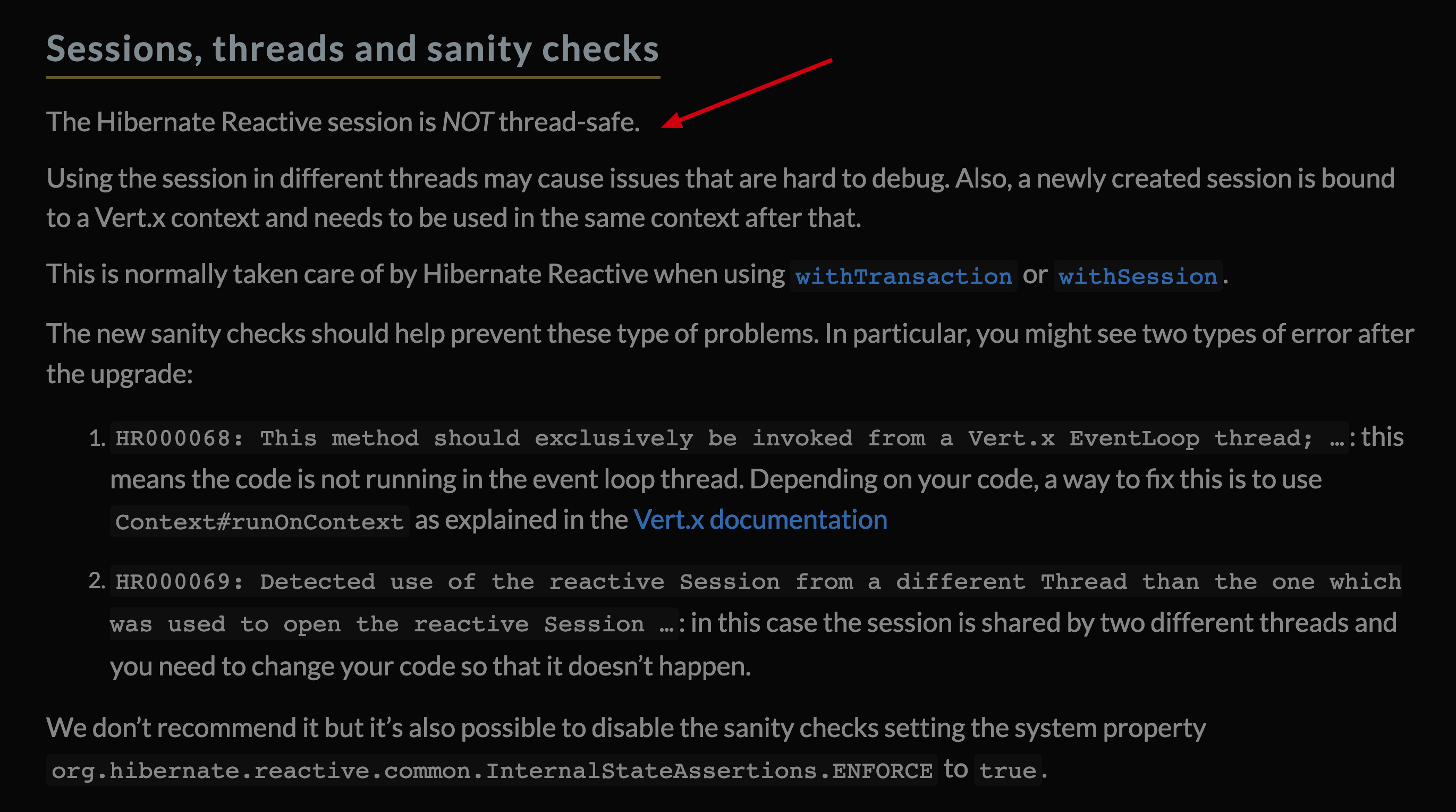
So if you have multiple database operations in one service method, you may meet the above problem easily. This is because of two reasons:
- One database operation do a commit, however another operation is running in parallel, but it maybe in same session, and it will hit transaction already committed problem.
- If multiple database operations are behind a web service API, because the operation is non-blocking, so during the execution process, the backed serving
vert.xthread maybe switched.
With my experience, to solve the complex transaction problem, better to encapulate one database operation into one web service, and a service logic can be combined by several web services. This greatly simplify the database transaction management.
The last topic I want to talk about is Quarkus Context Propagation. Here is the article explains the Quarkus Context Propagation:
Sometimes we need a Quarkus managed thread or Executor to execute our logic manually, but we need the whole context managed by Quarkus(for example, we need the injected components). Here is the example usage of ManagedExecutor I used in my project:
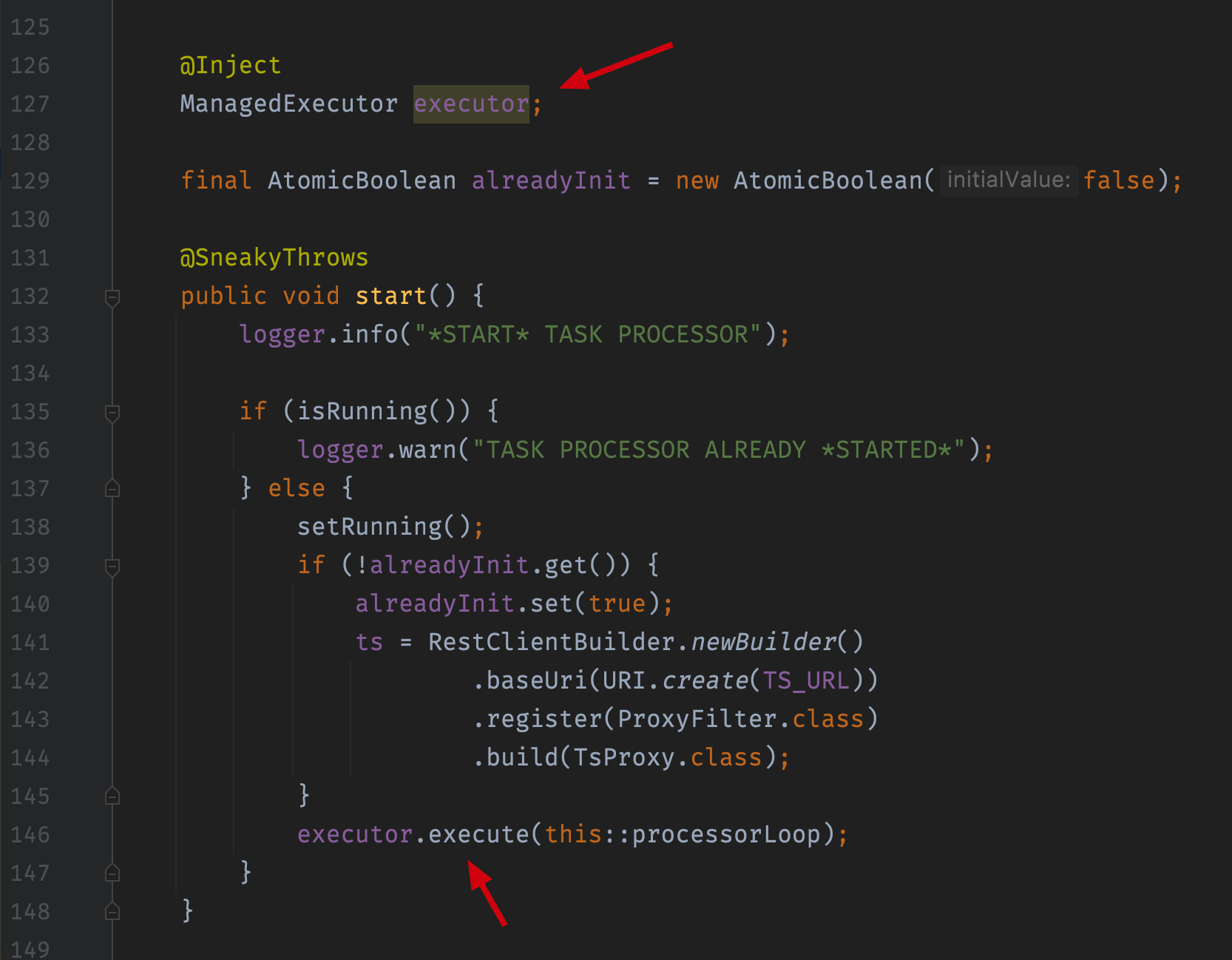
The ManagedExecutor has all the injected components as context:
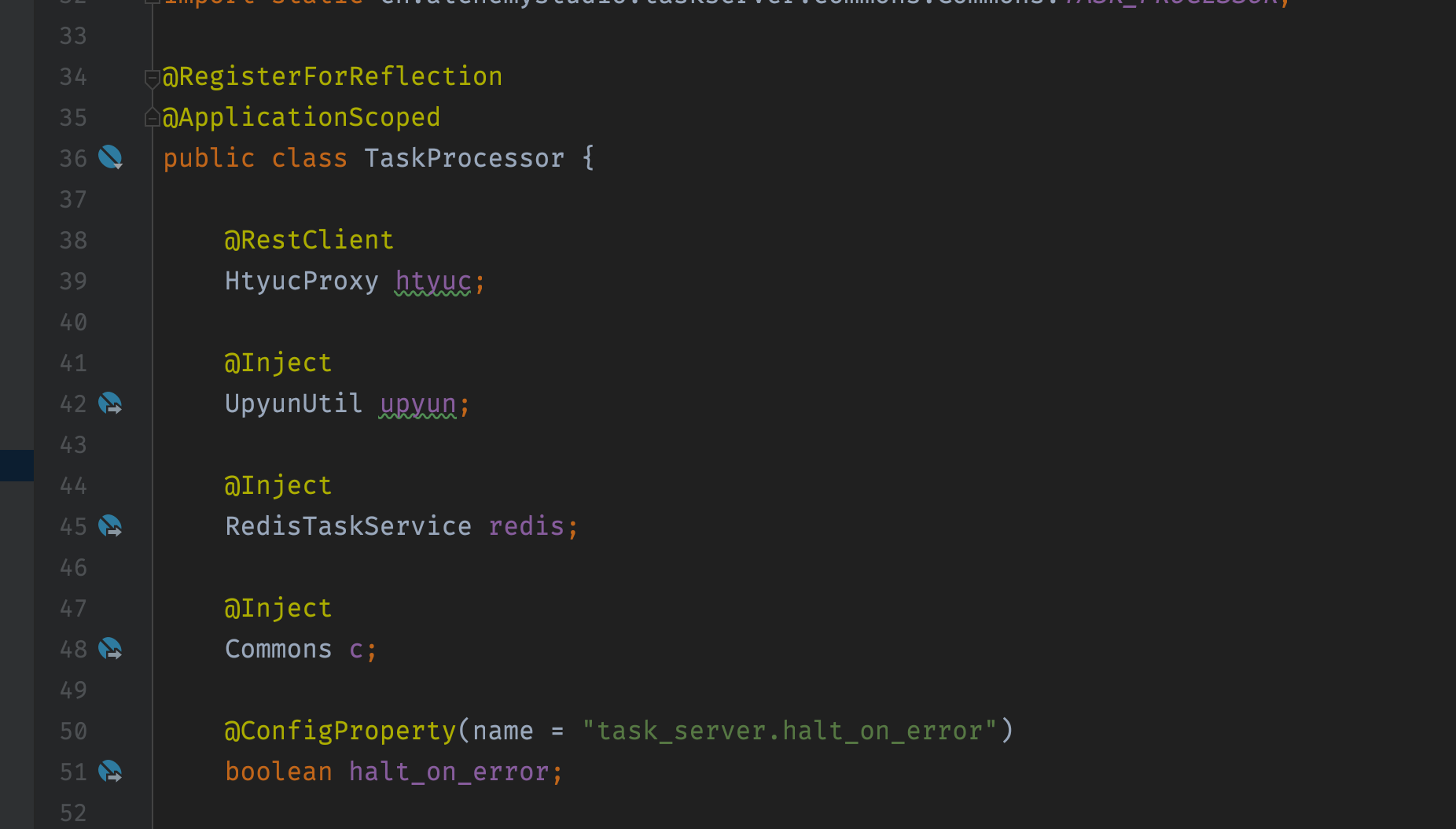
In above all the components managed by Quarkus is included in ManagedExecutor context. Above are some of my using experiences of Quarkus Reactive.
Hope it’s interesting to read :D