Some Quarkus Native Build Experiences
I played with the Quarkus native build recently and there are some things needs to be noted.
Firstly you need to have a GraalVM1 release of Java to be installed. I use SDKMAN2 to manage my Java releases, so I can get a list of Java releases with the sdk command:
$ sdk list java
Here is the output of the command:
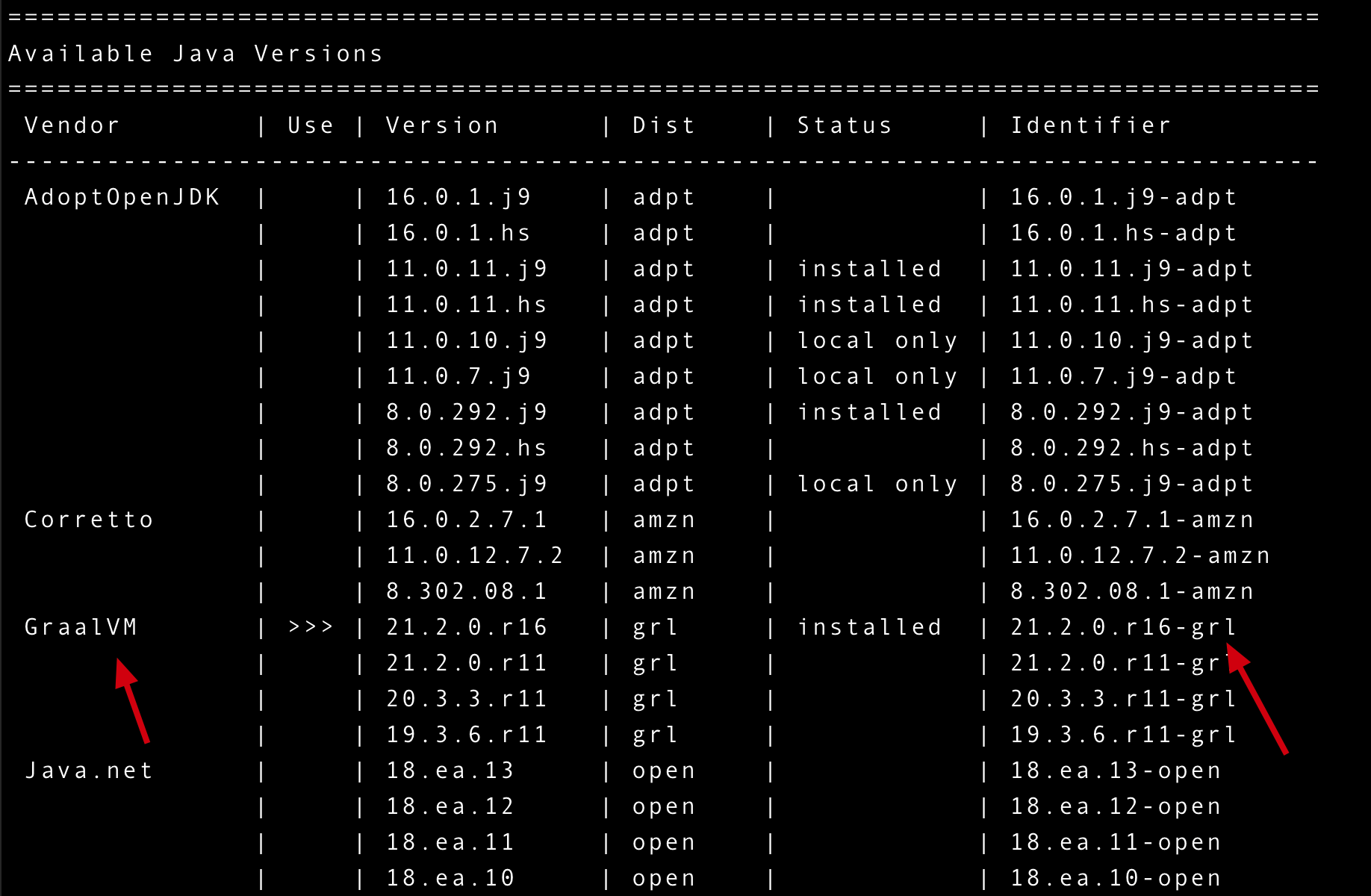
From above output we can see there are several versions of GraalVM, and I installed the newest version with the command:
$ sdk install java 21.2.0.r16-grl
Because I have already installed the release, so it will output like this:

If you haven’t installed the version in your environment, it will start the install process, and ask you if you want to switch to the installed Java release by default. Just selecting y and your environment will start to use this version of Java.
GraalVM provides the ability to compile Java code into the native binary code, which boosts the performance of the Java program. Before doing the native build, we need to use the gu command provided by the GraalVM release and install the native-image tool with the command:
$ gu install native-image
And here is the output on my computer:

Because I have installed the native-image tool, so the output is like above. If you don’t have native-image tool installed, the above command will start the installation process.
After the environment is prepared, now we can compile our Quarkus project into native binary. Here is the command to do the native build:
$ mvn package -Pnative -DskipTests
The native build process is much slower than Java build process, and the build process is very CPU and memory intensive:

And here is the output of the build process:
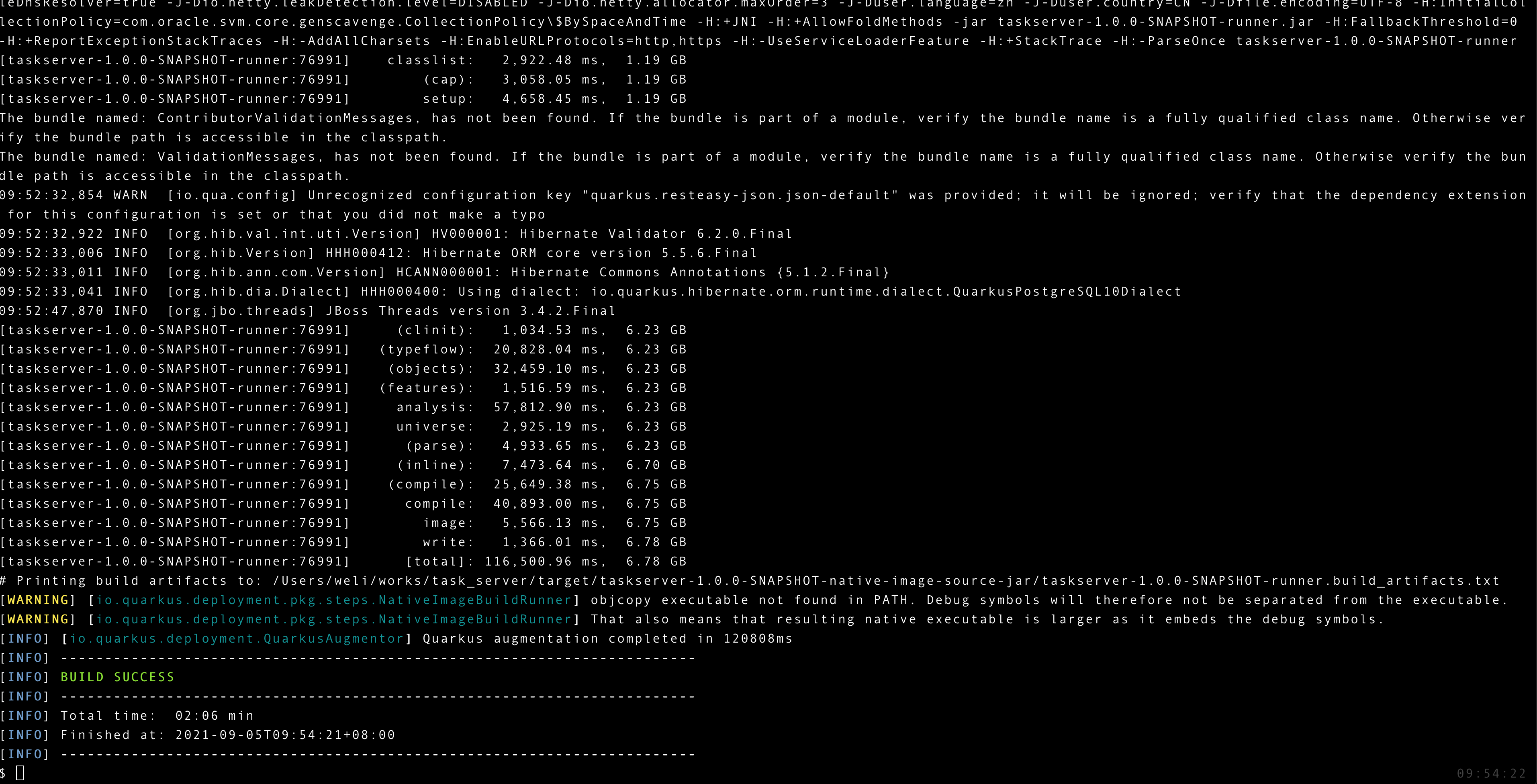
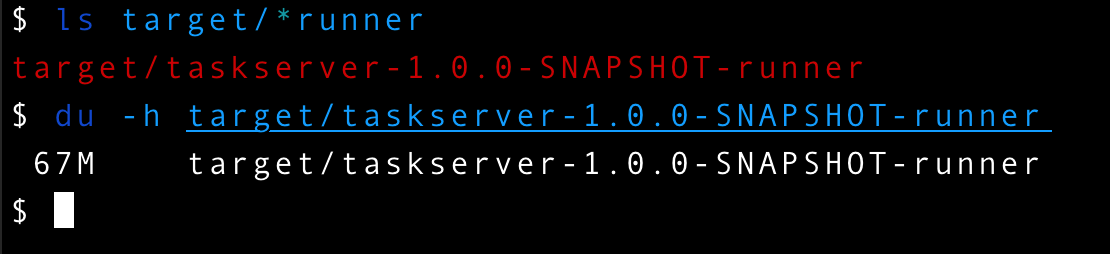
As you can see the native build process contains a lot of steps to transform the Java code into native binary executable. Finally we get a single executable file that contains the whole project:
We can run this executable file directly to start the project:
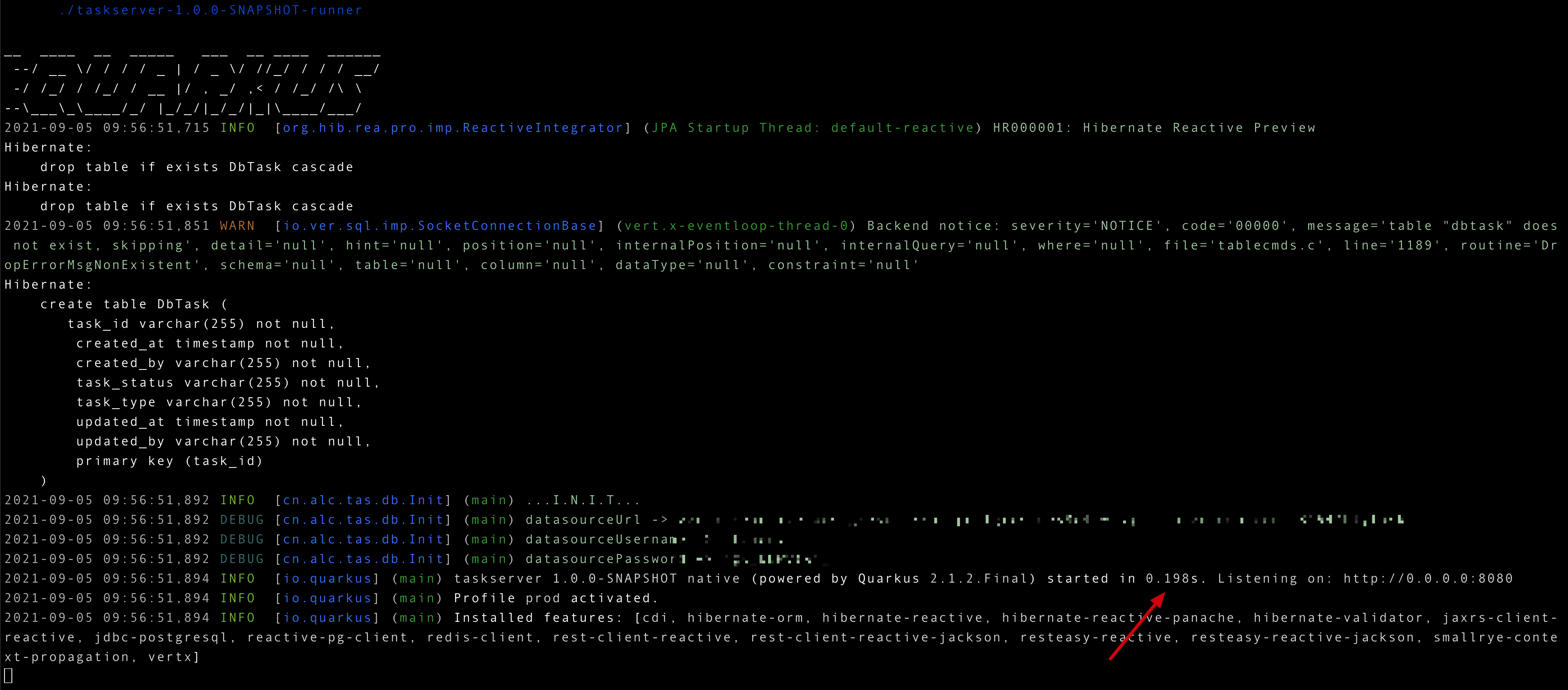
As the screenshot shown above, the whole project is a single executable file, and the project startup process is blazing fast. The memory footprint is also much smaller than the Java compiled byte code.
Nevertheless, there are some points that need to be noted to use the native build. The first thing need to be noted is that, for native build, it will automatically use your prod profile in your application.properties:
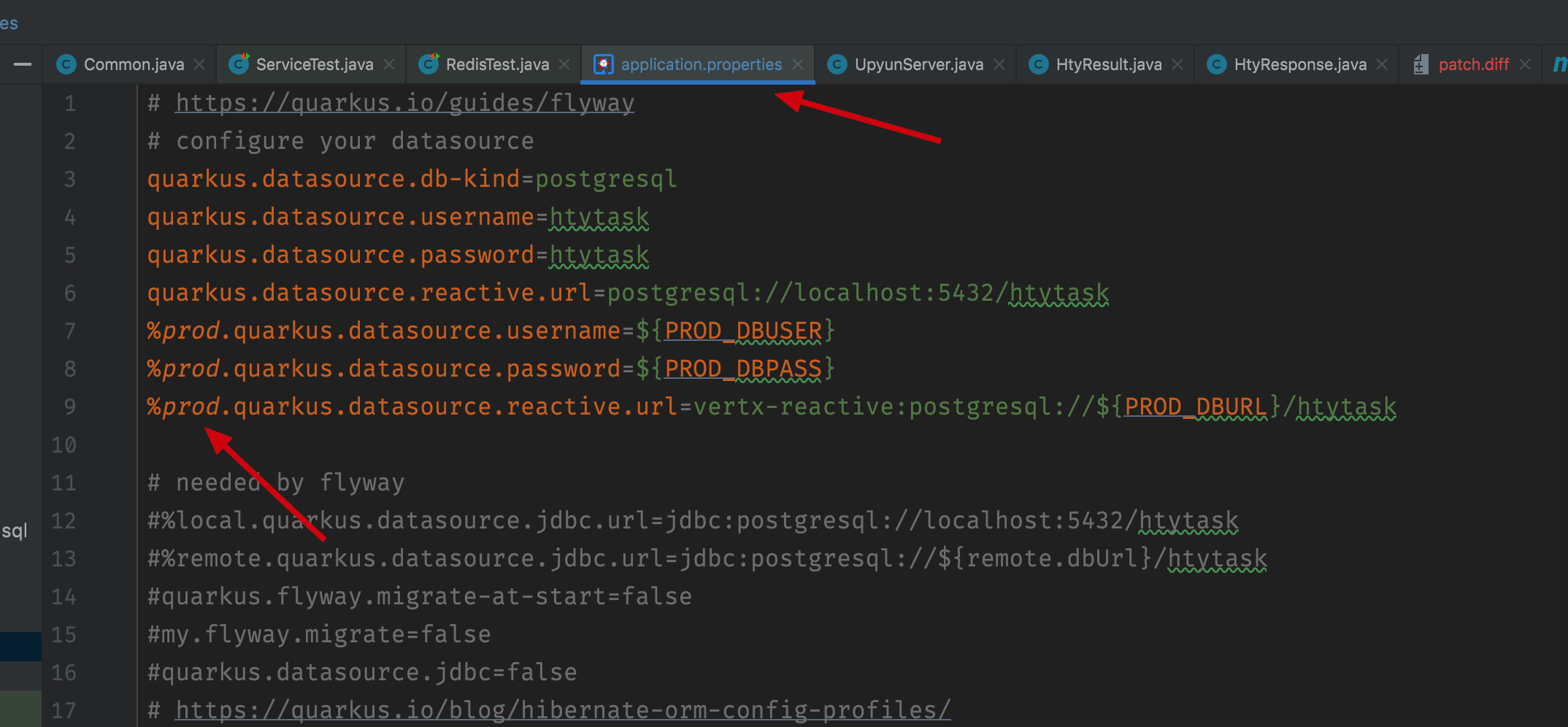
As the screenshot shown above, the %prod config properties will be picked during native build process. This can be seen during your binary executable file startup process:

In addition, the major difference between Java compilation and binary compilation is that, after compiling the Java code into binary code, we lose all the runtime information exists in bytecode format, which means, we can’t use the reflections during runtime in binary code, so all the code that rely on runtime reflection may not work properly after compiling into binary code.
For example, if you use Jackson3 to serialize a Java class into JSON like this:

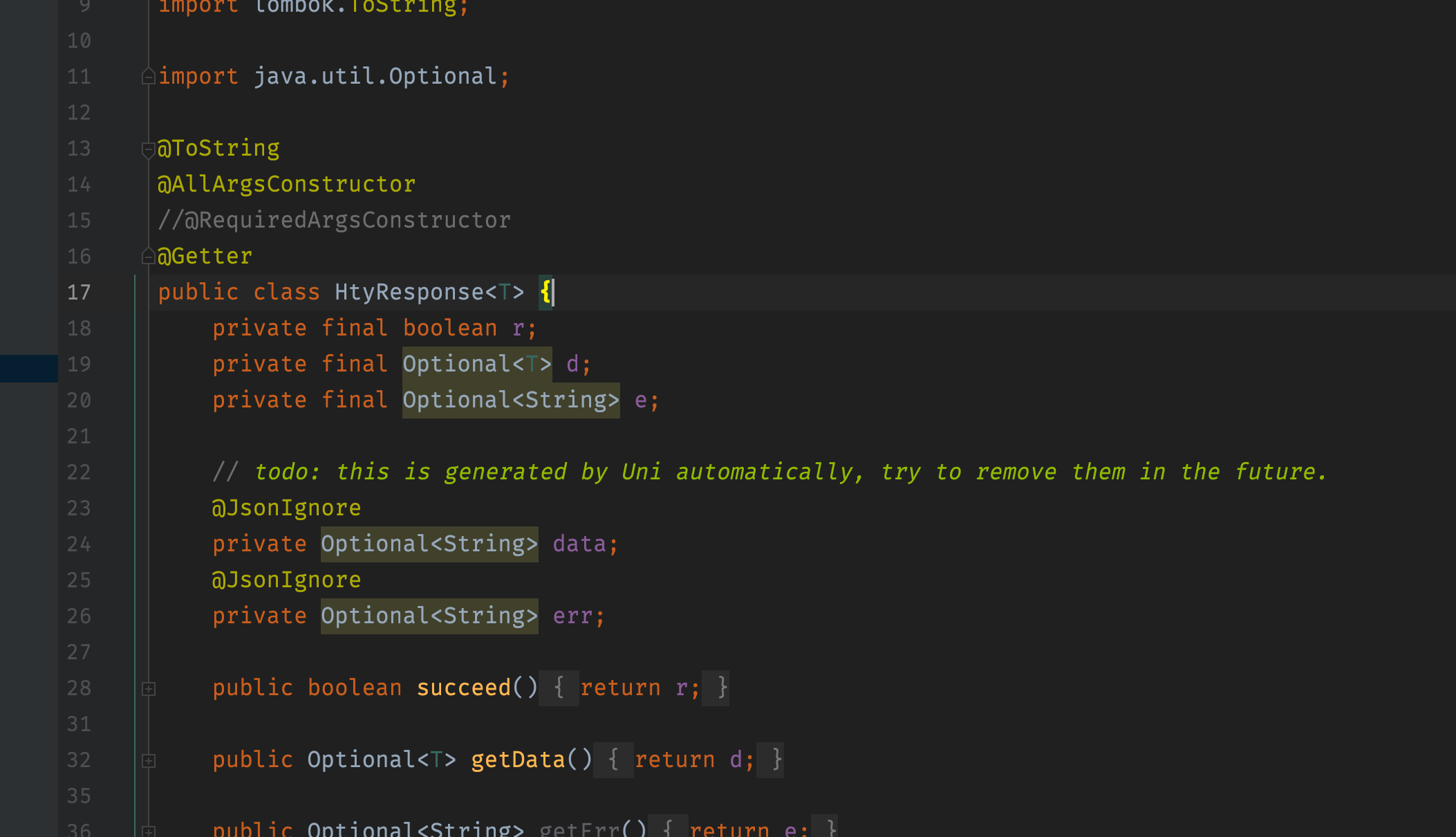
This will work for Java build, but after building it into native binary, and start the executable, you will get error like this:

The error message tells us that Jackson can not serialize our class anymore, and we need to annotate our class with @RegisterForReflection. So we should follow the instruction and annotation our class:
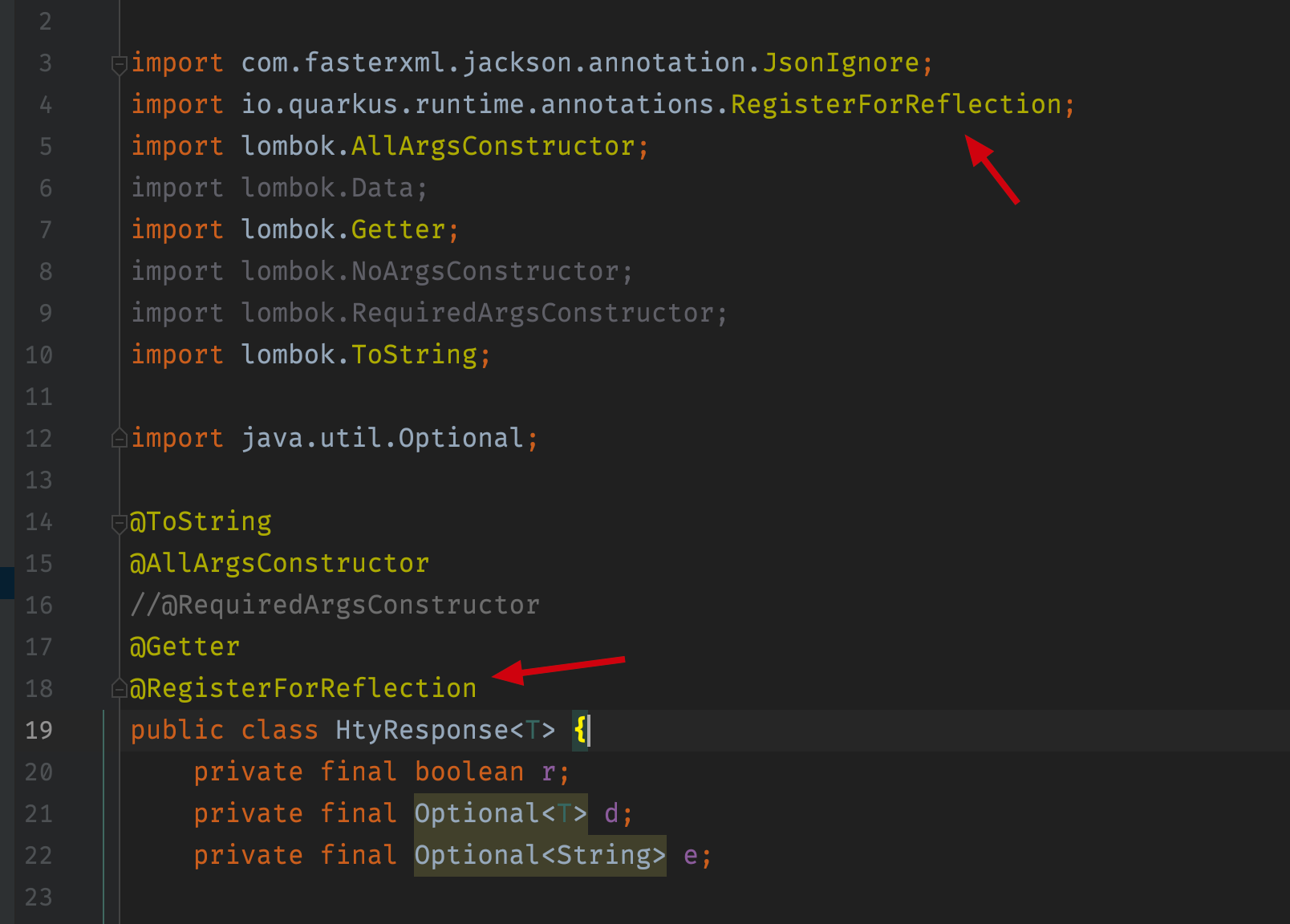
And then Jackson can serialize our class properly after the code is compiled to binary. The other thing need to be noted is that, currently if you are using Hibernate in your project like this:

And if you are willing to use the schema-update policy provided by Hibernate in your application.properties:
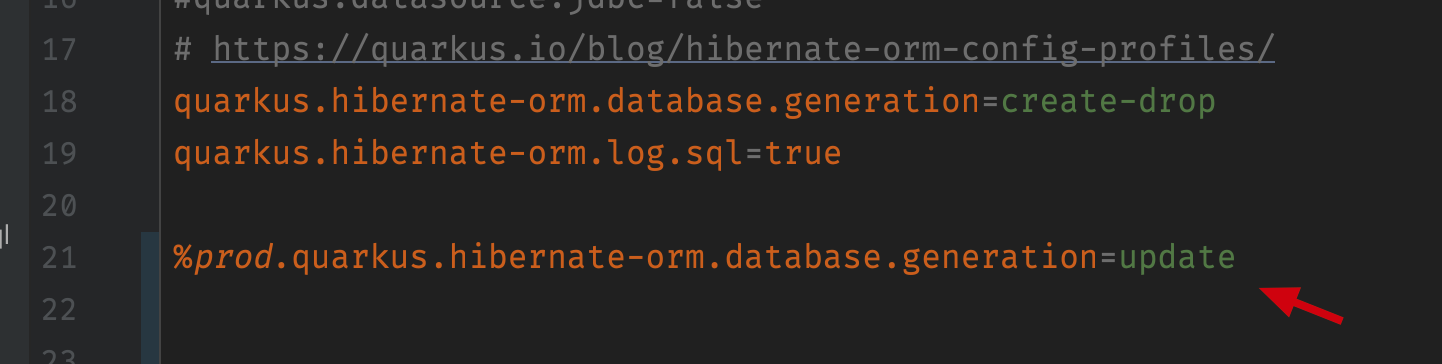
You will find it doesn’t work during executable start process:
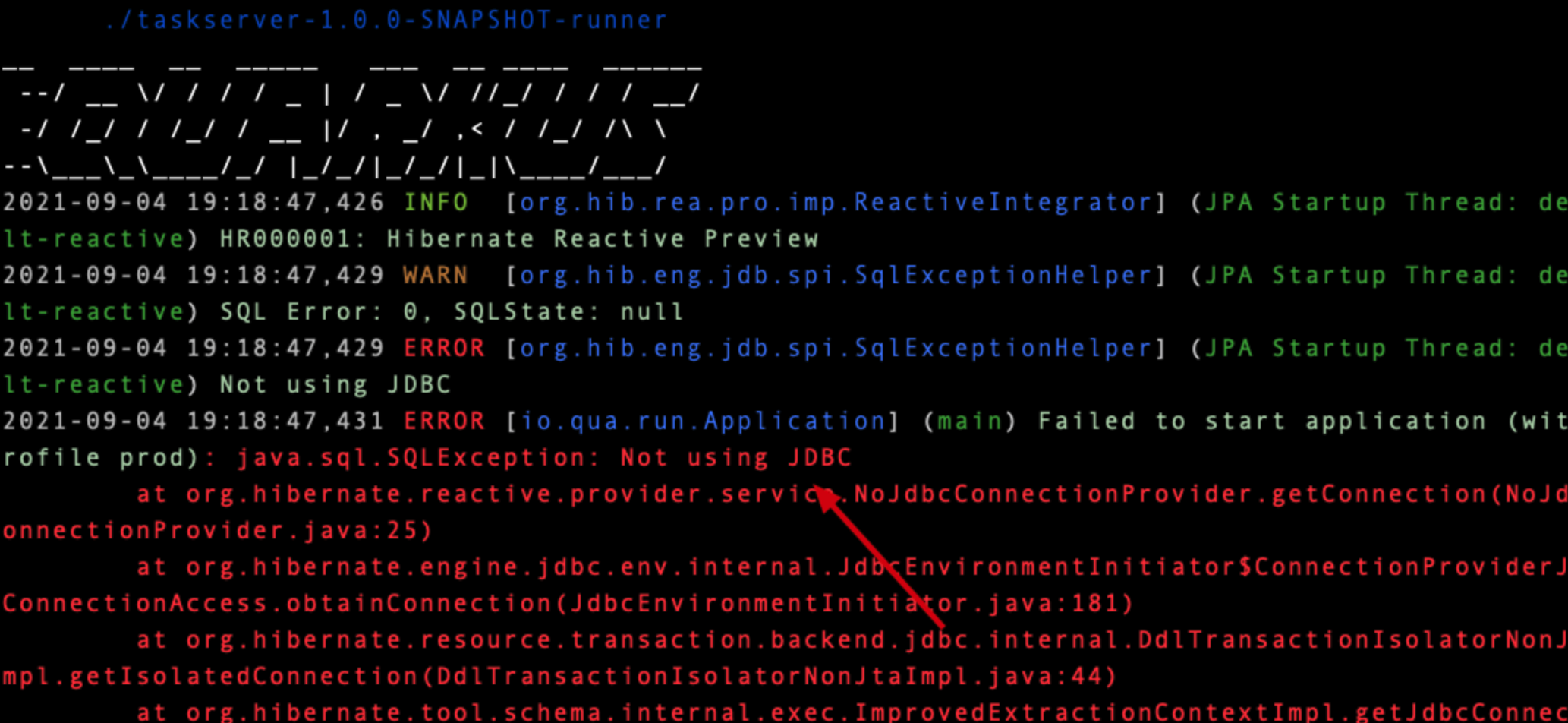
This is because currently the update policy has problem for hibernate-panache-reactive(And not only exists in binary build I guess), and here are some relative links to the issue:
- Getting exception “Not using JDBC” while using quarkus-hibernate-reactive-panache with quarkus-reactive-mysql-client - (Quarkus 1.12.2.Final) - Stack Overflow
- Reactive Postgres Client and Flyway/Postgres does not work together · Issue #2751 · quarkusio/quarkus · GitHub
So we may need to wait Quarkus/Hibernate team to fix this soon.
完毕.